
Snowflake Document AI : Unlocking Insights from Unstructured Data
Fun fact! Around 80%-90% of the world’s data is unstructured. I was shocked when I read this fact. The unstructured data contains images, emails, PDF files social media posts, and other formats. Even though it is widely present 70% of data is not being used to drive insights and get analytics.
As a Data Engineer, you must have developed many data pipelines using different tools for structured or semi-structured data. But have you ever built a single pipeline for highly unstructured data like PDFs, Emails, data captured from images, etc? The answer probably might be NO. It’s obvious that extracting data from unstructured data is really tough.
In the Gen AI and ML era, It is no longer a tedious job to do. Thanks to the latest feature from Snowflake, It’s Document AI. This is a game-changing innovation, a powerful feature built to extract and analyze data from unstructured data.
Document AI: Intelligent Document Processing
Snowflake Document AI is the latest feature that comes under AI & ML. It is an AI & ML-powered feature that extracts data from unstructured documents such as PDFs, scanned images, and emails. It integrates with other Snowflake features smoothly, which enables users to analyze extracted information without any other tools or ETL process.
How Does Snowflake Document AI Extract Data?
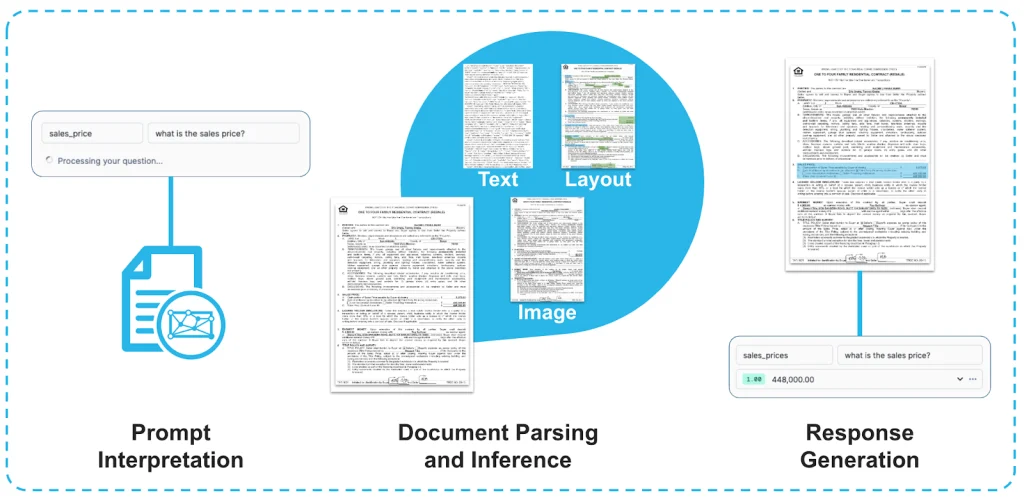
extraction info from the document
The process of extracting data from unstructured documents involves several key steps:
- Document upload to stage
- Users upload unstructured documents (PDFs, scanned images, or text-based files) into Snowflake’s internal or external stage.
- Snowflake preprocesses it to check for readability and stores metadata.
- Information Extraction
- Optical Character Recognition (OCR): It converts PDF files and images to natural English readable text.
- Named Entity Recognition (NER): It identifies context-based important tags like dates, names, addresses, invoice numbers, etc.
- Data Structure & Storage
- The extracted information is converted into structured JSON formats.
- The structured data is loaded into a snowflake table for querying, analytics, and reporting.
- Querying & Analytics
- Once the data is loaded to tables, users can perform SQL queries, ML modeling, and advanced analytics.
- It enables organizations to derive hidden insights from unstructured data.
What’s the Technology Behind Snowflake Document AI?
Snowflake Document AI leverages a combination of advanced AI/ML models and proprietary algorithms to extract and structure data efficiently. Here are some of the key technologies behind the scenes:
- Optical Character Recognition (OCR)
- OCR technology helps convert images, scanned text, and PDFs into digital text.
- Snowflake uses deep-learning-based OCR models to improve accuracy in handwritten and printed text recognition.
- Natural Language Processing (NLP)
- NLP models identify and categorize key entities, sections, and tables within a document.
- Advanced language models (similar to Transformer-based AI models like BERT or GPT) enable context-aware text extraction.
- Named Entity Recognition (NER)
- Categories and identifies important context-based data tags such as Names, dates, addresses, invoice numbers, legal terms, etc.
- It can also highly classify personal and sensitive data and tag it for business-critical applications.
- Machine Learning-Based Pattern Recognition
- Uses ML algorithms to detect tables, forms, and structured data patterns within documents.
- It ensures that extracted data has its contextual meaning and relationships.
- Snowflake’s Native AI Integration
- Snowflake Document AI is automatically integrated into Snowflake’s ecosystem, It means users can perform SQL-based queries on extracted data without needing any additional ETL processes.
- The processed data is directly available for BI tools, dashboards, and machine learning applications.
Oh… A lot of theory. Now it’s time to make your hands dirty. Head towards now Snowflake Snowsight interface. We will go step by step to extract the data from PDF files specifically internet bills that are uploaded to an internal stage in Snowflake. We’ll then insert the extracted information into a Snowflake table. Let’s get started!
Step 1: Create the database and the schema.
-- Create the database CREATE DATABASE TESTDB; -- Create the schema inside the database CREATE SCHEMA TESTDB.TESTSCHEMA; USE database testdb; USE schema testschema;
Step 2: Create an internal stage.
CREATE OR REPLACE STAGE airtel_stage DIRECTORY = (ENABLE = TRUE) ENCRYPTION = (TYPE = 'SNOWFLAKE_SSE');
Step 3: Create a stream on stage.
CREATE STREAM airtel_stream ON STAGE airtel_stage; SHOW STREAMS; ALTER STAGE airtel_stage REFRESH;
Step 4: Create a table.
-- The metadata about the pdf file will be loaded to the first four columns and the information -- extracted will be loaded to the json_content column in JSON format which we need to parse JSON later. CREATE OR REPLACE TABLE airtel_bill ( file_name VARCHAR, file_url VARCHAR, file_size VARIANT, last_modified VARCHAR, json_content VARCHAR );
Step 5: Create a Document AI model
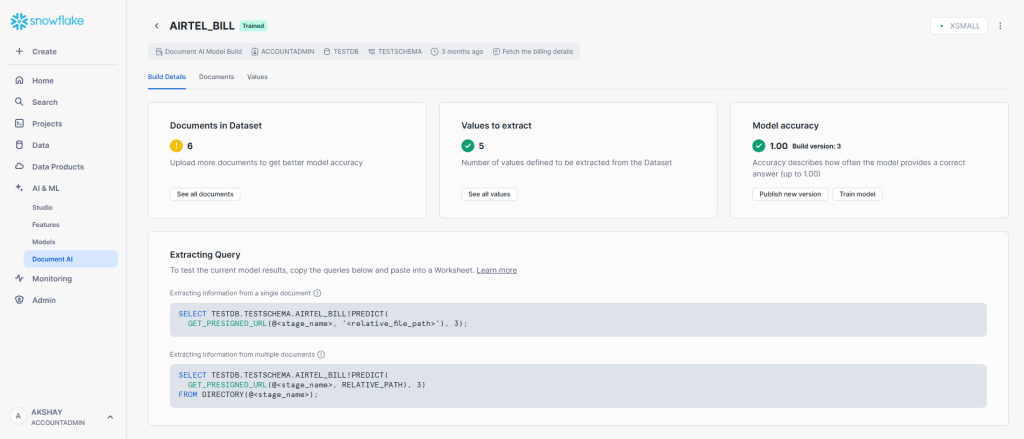
Document AI Model
- Go to the AI & ML menu from the left panel and select Document AI.
- Click on the “+ Build” button top right corner to create a new model.
- Provide the name of the model, database name, schema name, and description.
- Click on the newly created model.
- Go to the Document section and add a few test PDF files to train the model.
- Go to the Values section and click on the Manage Values button.
- Click on the “+ value” button to add a new Value. Provide a key name and question to extract the information.
- Example 1: The key name is “invoice_no” and the question would be “Extract the invoice number from this document”.
- Example 2: The key name is “bill_period” and the question would be “What is the billing period”.
- You can add as many values as you need. It will try to extract the information from the document and If the extracted value is correct click on the “OK” button.
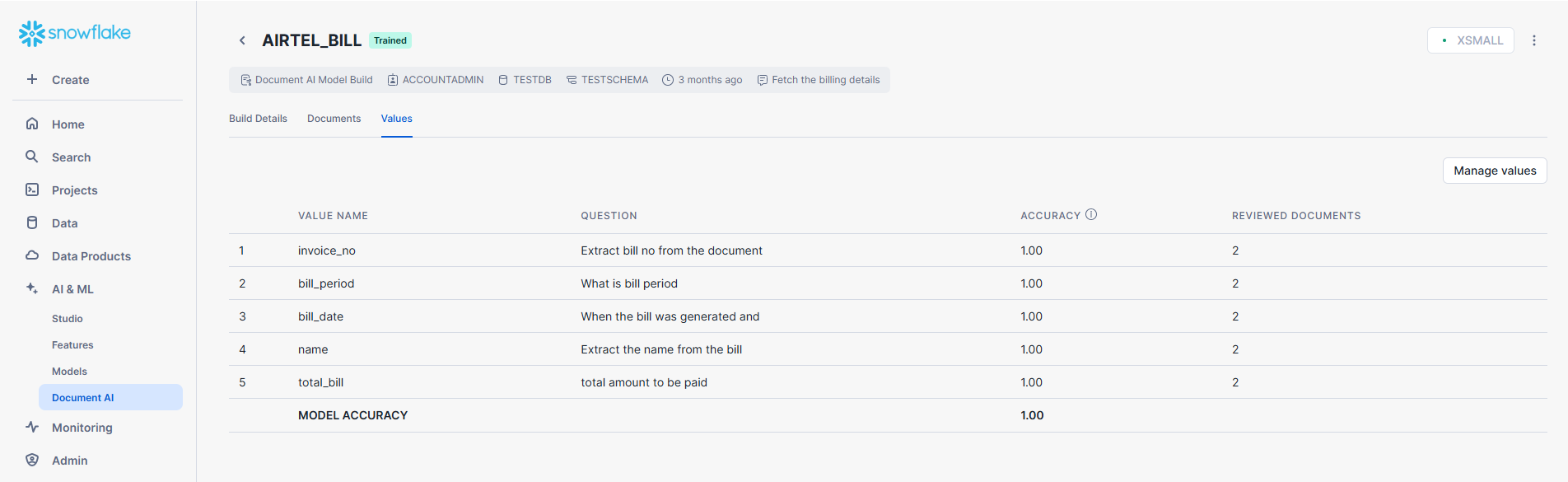
Manage Values
- Now run this model on all of your test files and check whether it is extracting correct values or not. If not you have to change the format of your question so that it will extract correct information.
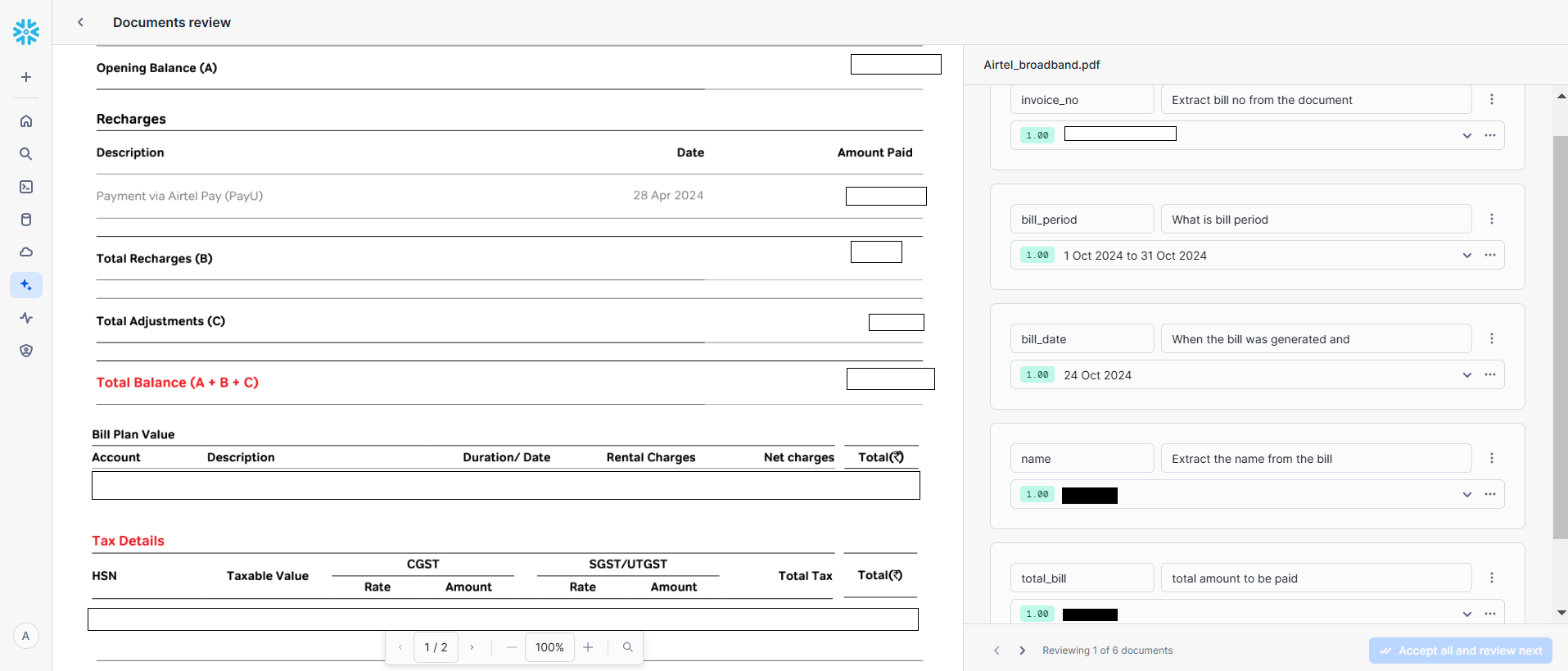
Extracting Info
- For testing try to extract the information from the files that have different formats because it will make your model efficient for any document.
- Publish the document. It will show the “latest version” of your model and “extract a query section” to get the values from the document.
Step 6: Create a task.
-- Create a new task which will run interval of 1 minute and process the file uploaded to internal stage and loads the data to table airtel_bill.
-- <model_name>!PREDICT() is the syntax to use to get the extracted data from a uploaded file.
CREATE OR REPLACE TASK load_new_file_data
WAREHOUSE = XSMALL
SCHEDULE = '1 minute'
COMMENT = 'Process new files in the stage and insert data into the airtel_bill table.'
WHEN SYSTEM$STREAM_HAS_DATA('airtel_stream')
AS
INSERT INTO airtel_bill (
SELECT
RELATIVE_PATH AS file_name,
file_url AS file_url,
size AS file_size,
last_modified,
AIRTEL_BILL!PREDICT(GET_PRESIGNED_URL('@airtel_stage', RELATIVE_PATH), 3) AS json_content
FROM airtel_stream
WHERE METADATA$ACTION = 'INSERT'
);
ALTER TASK load_new_file_data RESUME;
Step 7: Show the extracted data by parsing the JSON-type column
-- Use of LATERAL FLATTEN function to parse the JSON Object SELECT file_name, file_url, file_size, last_modified, b.value:value::STRING AS bill_date, p.value:value::STRING AS bill_period, i.value:value::STRING AS invoice_no, n.value:value::STRING AS name, t.value:value::STRING AS total_bill, o.value as ocr_score FROM airtel_bill, LATERAL FLATTEN(INPUT => PARSE_JSON(json_content):bill_date) b, LATERAL FLATTEN(INPUT => PARSE_JSON(json_content):bill_period) p, LATERAL FLATTEN(INPUT => PARSE_JSON(json_content):invoice_no) i, LATERAL FLATTEN(INPUT => PARSE_JSON(json_content):name) n, LATERAL FLATTEN(INPUT => PARSE_JSON(json_content):total_bill) t, LATERAL FLATTEN(INPUT => PARSE_JSON(json_content):__documentMetadata) o;
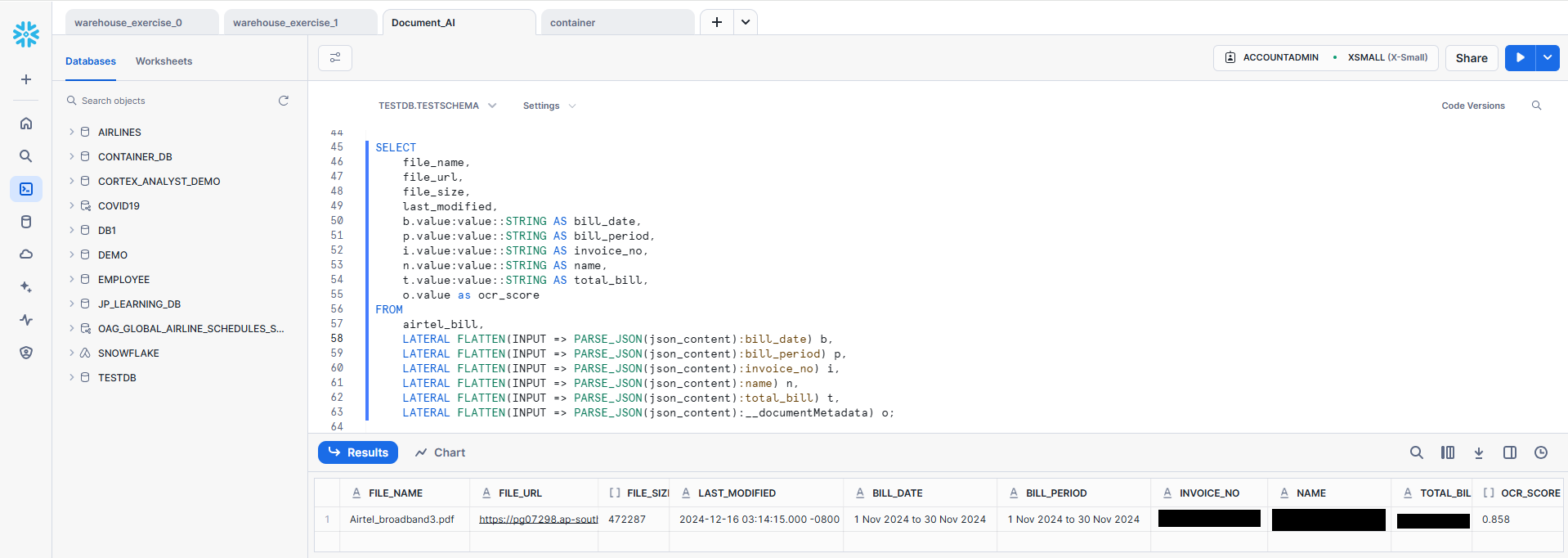
Info Loaded into the table
Conclusion
Unstructured data has long been a missed opportunity for analytics. However, with the power of AI and ML, Snowflake Document AI is transforming the way businesses extract and utilize information from PDFs, images, and other unstructured sources. By leveraging OCR, NLP, and ML-based data structuring, Snowflake Document AI ensures that enterprises unlock hidden value, drive efficiency, and enhance decision-making. If your organization deals with large volumes of unstructured data, it’s time to explore how Snowflake Document AI can revolutionize your data strategy.
