
RSS FEED PARSING using PySpark
Introduction
An RSS (Really Simple Syndication) feed is an online file that contains details about each piece of content a site has published. RSS feeds are a common way to distribute updates from websites and blogs. These feeds are often provided in XML format, and Python offers several tools to parse and extract information from them. This blog post will explore how to parse XML RSS feeds using Pyspark.
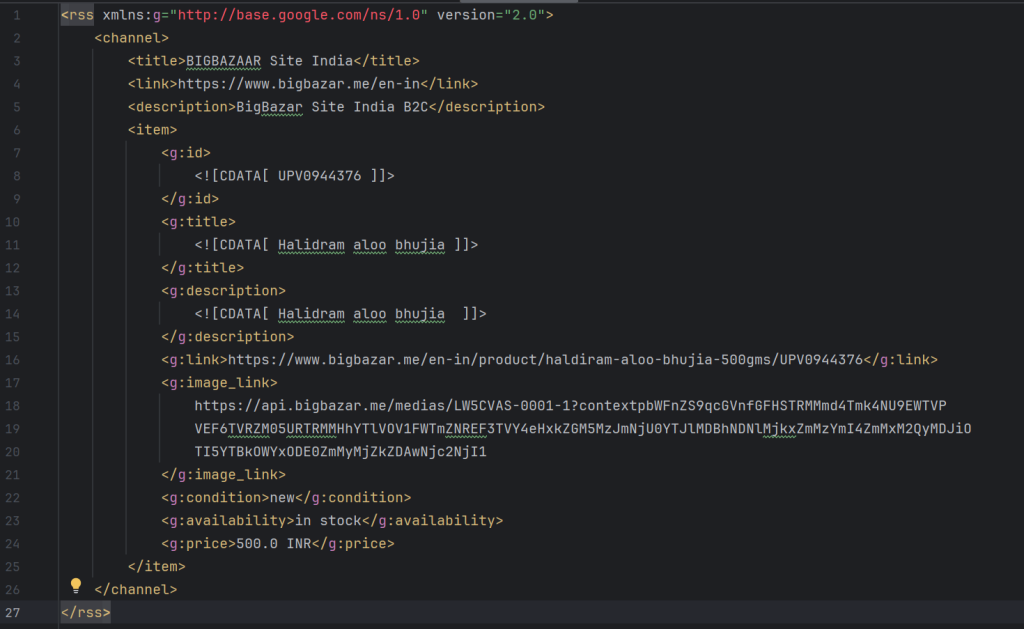
RSS Feed Test Sample
Prerequisites
Before we begin, ensure you have Python installed on your system (Link to install Python- https://www.python.org/downloads/ ).
Understanding RSS Feeds and XML Parsing
RSS feeds contain articles, news items, or other updates in a structured XML format. To work with these feeds, we can use the xml.etree.ElementTree or feedparser library in Python, provides an efficient way to parse XML data. Keep in mind that RSS feeds may contain additional elements beyond title, link, and description. If we use xml.etree.ElementTree we will have to adapt the parsing code to extract other elements of interest. We will be understanding the usage and implementation of the feedparser module in this blog.
| Feature | xml.etree.ElementTree | Feedparser |
| Primary Use | General XML parsing and manipulation | Parsing RSS and Atom feeds |
| Library Type | Built-in Python standard library | Third-party library (requires installation) |
| Installation | No installation required | Requires installation (pip install feedparser) |
| Focus | General XML data structures | Syndication formats (RSS, Atom) |
| Parsing Capability | Parses XML documents into ElementTree objects | Parses RSS and Atom feeds into structured data |
| XPath Support | Basic XPath support for querying XML | None; focused on feed data extraction |
| Element Handling | Handles elements, attributes, and text with tree structure | Focuses on extracting feed metadata and entries |
| Feed Format Handling | Not specialized for RSS/Atom feeds | Specialized for handling various feed formats |
| Data Access | Manual traversal and querying of XML elements | Structured API for accessing feed information |
| Modification Capability | Allows creation and modification of XML structures | Read-only; does not modify feeds |
| Error Handling | Basic error handling for XML parsing | Includes error handling for feed parsing issues |
| Output Structure | Provides ElementTree objects with tag and text | Provides a structured dictionary-like object for feeds |
| Common Use Cases | General XML tasks, such as configuration files or data interchange | Aggregating and processing feed data from news sources |
| Performance | Efficient for standard XML tasks | Optimized for feed parsing but may be less flexible for non-feed XML |
| what they can parse | <library> <book> <title>The Great Gatsby</title> <author>F. Scott Fitzgerald</author> <year>1925</year> </book> <book> <title>To Kill a Mockingbird</title> <author>Harper Lee</author> <year>1960</year> </book> </library> |
<?xml version=”1.0″ encoding=”UTF-8″ ?> <rss version=”2.0″> <channel> <title>Sample RSS Feed</title> <link>http://www.example.com</link> <description>This is a sample RSS feed</description> <item> <title>First Post</title> <link>http://www.example.com/first-post</link> <description>This is the description </description> <pubDate>Mon, 01 Oct 2023 12:00:00 GMT</pubDate> </item> </channel> </rss> |
Steps to Parse XML RSS Feeds
Let’s dive into the steps to parse an XML RSS feed using Python
Import the Required Libraries: Start by importing all the necessary libraries.
Note: Universal Feed Parser is a Python module that downloads and parses syndicated feeds. It can handle RSS 0.90, Netscape RSS 0.91, Userland RSS 0.91, etc, Atom 1.0 and more, CDF, and JSON feeds. It can also parse popular extension modules, like Dublin Core & Apple’s iTunes extensions. To use Universal Feed Parser, you can use Python 3.8 or later versions. Universal Feed Parser is not meant to run standalone; it is a module for you to use as part of a larger Python program. Universal Feed Parser is very easy to use; it has one primary public function, “parse”. The parse function can take several arguments, but only one of them is required, and it can be a URL, a local filename, or a raw string containing feed data in any format.
Let’s take a deep dive into parsing RSS Feed using Pyspark
1. Initialize Spark Session, Fetch, and Load RSS Feed: Create a Spark Session and upload files from remote or URL.
from pyspark.sql import SparkSession
import feedparser
import glob
import os
import sys os.environ['PYSPARK_PYTHON'] = sys.executable
# Initialize SparkSession
spark = SparkSession.builder \
.appName("RSS Feed Processor") \
.getOrCreate()
file_names = glob.glob('c:/Users/Ashita Kumar/Downloads/*.xml')
2. Declare Schema for the Data frame.
# Define schema for DataFrame
schema = StructType([
StructField("file_name", StringType(), True),
StructField("feed_title", StringType(), True),
StructField("feed_link", StringType(), True),
StructField("feed_description", StringType(), True),
StructField("ID", StringType(), True),
StructField("title", StringType(), True),
StructField("description", StringType(), True),
StructField("link", StringType(), True),
StructField("image_link", StringType(), True),
StructField("condition", StringType(), True),
StructField("availability", StringType(), True),
StructField("price", StringType(), True),
StructField("name", StringType(), True),
StructField("points_value", StringType(), True),
StructField("ratio", StringType(), True),
StructField("item_group_id", StringType(), True),
StructField("brand", StringType(), True),
StructField("product_type", StringType(), True),
StructField("color", StringType(), True),
StructField("size_of_product", StringType(), True),
StructField("gender", StringType(), True),
StructField("sale_price", StringType(), True),
StructField("custom_label_0", StringType(), True),
StructField("custom_label_1", StringType(), True),
StructField("fb_product_category", StringType(), True),
StructField("age_group", StringType(), True),
])
3. Iterate through all files and parse the file using Feedparser. Use the requests library to fetch the RSS feed from a URL and load it into a feed object. We can load the RSS feed from a URL or even a storage location.
# Create an empty list to store rows
rows = []
# Iterate through all files
for file in file_names:
print("Processing file:", file)
# Parse the XML file using feedparser
feed = feedparser.parse(file)
# Extract feed details
feed_title = feed['feed'].get('title', '')
feed_link = feed['feed'].get('link', '')
feed_description = feed['feed'].get('description', '')
# Title of the file
print("title of the feed ", feed['feed']['title'])
# Link of the Feed
print("link of the feed ", feed['feed']['link'])
# Description of the feed
print("description of the feed", feed['feed']['description'])

Output of print statements for feed details
4. Parse RSS Items: Iterate through the RSS items to extract relevant information.
# Iterate through feed entries
for entry in feed.entries:
row = {"file_name": "big_bazar_file", # Use the actual file name
"feed_title": feed_title,
"feed_link": feed_link,
"feed_description": feed_description,
"ID": getattr(entry, 'g_id', ''),
"title": getattr(entry, 'g_title', ''),
"description": getattr(entry, 'g_description', ''),
"link": getattr(entry, 'g_link', ''),
"image_link": getattr(entry, 'g_image_link', ''),
"condition": getattr(entry, 'g_condition', ''),
"availability": getattr(entry, 'g_availability', ''),
"price": getattr(entry, 'g_price', ''),
"name": getattr(entry, 'g_name', ''),
"points_value": getattr(entry, 'g_points_value', ''),
"ratio": getattr(entry, 'g_ratio', ''),
"item_group_id": getattr(entry, 'g_item_group_id', ''),
"brand": getattr(entry, 'g_brand', ''),
"product_type": getattr(entry, 'g_product_type', ''),
"color": getattr(entry, 'g_color', ''),
"size_of_product": getattr(entry, 'g_size', ''),
"gender": getattr(entry, 'g_gender', ''),
"sale_price": getattr(entry, 'g_sale_price', ''),
"custom_label_0": getattr(entry, 'g_custom_label_0', ''),
"custom_label_1": getattr(entry, 'g_custom_label_1', ''),
"fb_product_category": getattr(entry, 'g_fb_product_category', ''),
"age_group": getattr(entry, 'g_age_group', '')}
rows.append(row)
5. Parse and store RSS feed item values in data frames using spark. We can create a dataframe and use for analytics or store it in parquet as required.
# Create Spark DataFrame df = spark.createDataFrame(rows, schema=schema) # Show the DataFrame with specific columns df.show(truncate=False) # Stop the Spark session spark.stop()
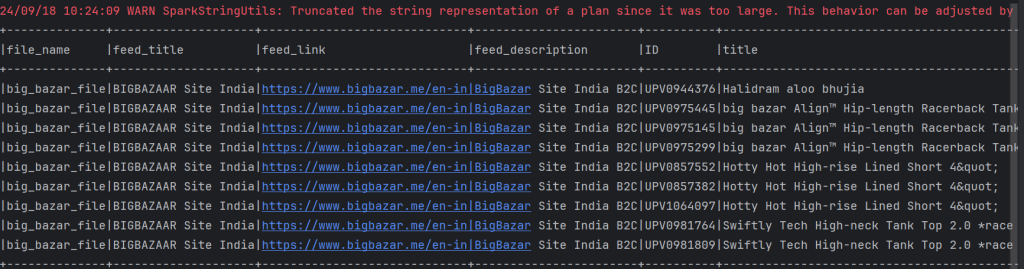
df.show() Output
Steps to Parse XML using Python
We can also parse RSS feeds using just Python. We’ll be able to achieve this using FeedParser and Pandas Libraries.
Pros and Cons of using RSS Feed
| PROS | CONS |
| 1. Aggregated Content | 1. Decreased Popularity |
| Aggregates content from multiple sources into one feed. | RSS feeds are less popular now compared to social media and other news aggregators. |
| 2. Customizable | 2. Requires an RSS Reader |
| Users can choose and customize their subscriptions based on interests. | Accessing RSS feeds requires an RSS reader or aggregator app. |
| 3. Real-Time Updates | 3. Inconsistent Quality |
| Provides immediate updates when new content is published. | Some feeds may be outdated or have inconsistent formatting. |
| 4. Ad-Free Experience | 4. Limited Multimedia Support |
| Delivers content without advertisements for a cleaner experience. | May not handle multimedia content like videos or interactive elements well. |
| 5. Privacy | 5. Fragmented Content |
| Subscribing to feeds does not require personal information, enhancing privacy. | Feeds are spread across various platforms, which can be disjointed. |
| 6. Offline Access | 6. Mobile Experience May Vary |
| Content can be accessed offline through many RSS readers. | Some RSS readers might not provide a good mobile or tablet experience. |
| 7. Easy Sharing | 7. Potential Information Overload |
| Feeds can be easily shared with others. | Users may experience information overload if they subscribe to too many feeds. |
| 8. No Algorithmic Filtering | 8. Static Content Delivery |
| Content is delivered in chronological order without algorithmic manipulation. | RSS feeds typically deliver static content without interactive features. |
Conclusion
Parsing XML RSS feeds using Python is a valuable skill for working with dynamic content from websites and staying up-to-date with the latest information. You can efficiently parse and extract data from RSS feeds by utilizing the feedparser library and the steps outlined in this blog post. Remember to adjust the parsing code based on the structure of the RSS feed you are working with.
