
Web Speech API
Overview
The Web Speech API aims to enable web developers to provide in a web browser, speech-input and text-to-speech output features. It is a JavaScript API that allows websites and web applications to incorporate the two key features of speech recognition and speech synthesis into their functionality. It works by translating speech from your device’s mic into text (speech recognition) and vice versa (speech synthesis). This API is particularly useful in creating more accessible and interactive web experiences, such as voice-driven web apps, assistive technologies, and other innovative web projects.
The API supports brief inputs (short commands) as well as continuous inputs. While the brief input makes it suitable for language translation, the capability of continuous extensive dictation makes it ideal for integration with the applause apps.
Browser compatibility
The Web speech API is still an experimental technology and is not universally supported by all browsers. As of now, it is supported by Google Chrome, Safari, and Android and partially supported on other browsers like Firefox and Microsoft Edge. It is always advised to check the current browser compatibility before implementing web speech api in your web application.
Why do we need Web Speech Technology?
Today’s AI models like Siri, Google Assistant, Alexa, and Cortana have become our constant digital companions, always ready to answer our questions, or play our favorite songs, navigate on maps while driving, turn off lights while lying in bed – all that activities are completely normal nowadays. But what if we move a step ahead and explore the many more possibilities of the use of voice navigation not only in specific apps but everywhere? Imagine you’re giving a presentation and changing over to the next slides each time you need to ask your friend “Next slide please”. you are in the kitchen, preparing dinner and you need to always wash your hands just not to dirty your screen while viewing the next step of the recipe on your mobile phone. All these limitations make me believe that web speech technology and voice-driven solutions have immense development possibilities in the future.
Speech Recognition
In the speech recognition interface, you speak into a microphone and then the speech recognition service processes human speech in readable text format. It provides the capability to recognize words and phrases. Nowadays it is widely used to access voice assistant apps to allow hand-free navigation of electronic gadgets. Speech recognition first samples the audio and removes any unnecessary background noise before separating the clip maps the speech voice against the dictionary of grammar and returns the text.
Let’s now deep dive into the workings of Speech recognition. First, we need to create a new SpeedRecognition object using the interface’s constructor. When we initialize the speech recognition object we don’t have to perform this action every time the user starts speaking. We also attach a handler to start the recognition process. Note that inside of the handler, we also set the recognition mode for the brief command or extensive dictation.
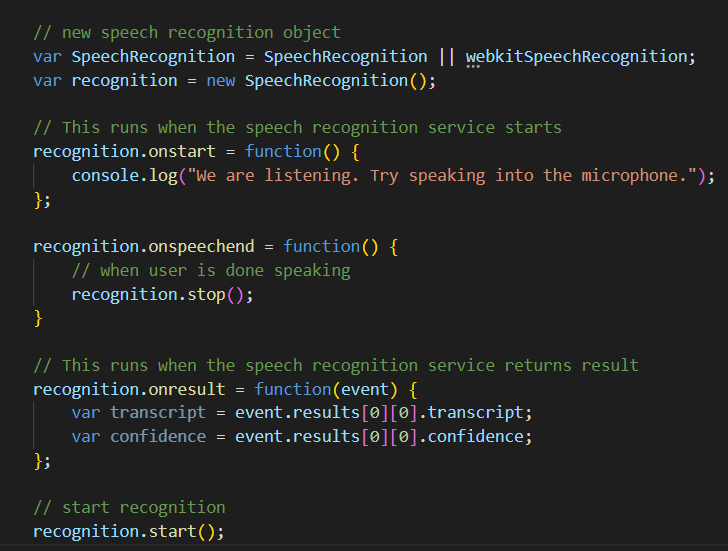
New speech recognition object
Once you speak into the microphone, the on-result event will be triggered, capturing the recognized speech. This speech is stored in the transcription variable. It returns both the interim results (when the speaker takes a pause while speaking) and the final results. The result can be processed as needed.
Speech Recognition callback functions
- onStart: onStart is triggered when the speech recognizer begins to listen to and recognize your speech. A message may be displayed to notify the user that the device is now listening.
- onStop: It generates an event that is triggered each time the user ends the speech recognition.
- onError: If the API fails to recognize speech, this event is triggered using the SpeechRecognitionError interface. It offers alternative input methods.
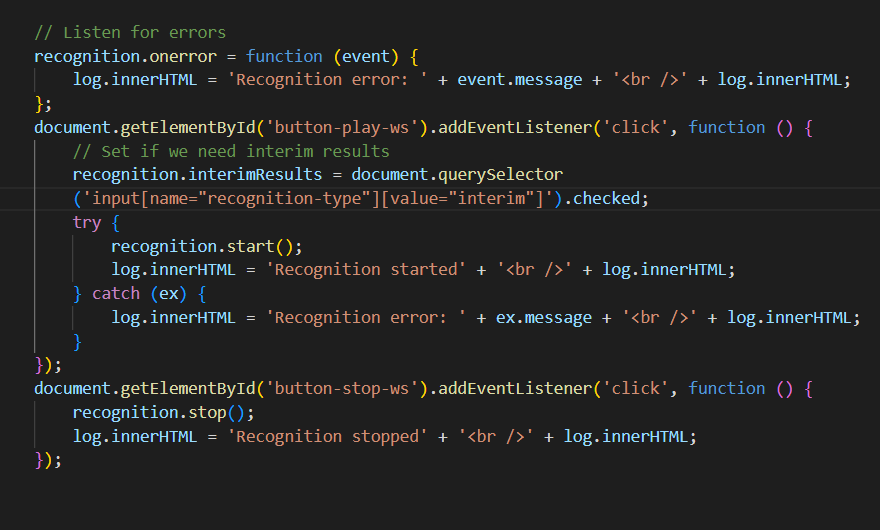
Speech recognition handler function
Speech Synthesis
Speech synthesis is the flip side of the Web Speech API. It allows you to convert text into spoken words. Speech synthesis means taking text from an app and converting it into speech, then playing it from your device’s speaker. Speech synthesis can be used for anything from driving directions to reading out lecture notes for online courses. Speech synthesis is highly beneficial in screen-reading for users with visual impairments. Its goal is to make the computer output clear, natural, and fluent speech. According to different levels of human speech function, speech synthesis can also be divided into three levels: text-to-speech (TTS) synthesis, concept-to-speech synthesis, from intention-to-speech to speech synthesis. These three levels reflect the different processes of forming speech content in the human brain and involve the high-level neural activities of the human brain. At present, the mature speech synthesis technology can only complete TTS synthesis, which is also often called TTS technology.
Now let’s know how you get your browser to speak. The driving interface for speech synthesis is SpeechSynthesis. First, we need to create an instance of the SpeechSynthesis interface. We retrieve a list of the voices available using SpeechSynthesis.getVoices() so the user can choose what voice they want. The language will default to your app or browser’s language unless specified otherwise using the .lang attribute.
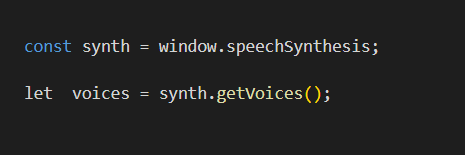
create a instance of Speech Synthesis controller
Create an instance of SpeechSynthesisUtterance interface contains the text from the input the service will read, as well as information such as language, volume, pitch, and rate. After specifying these values, put the instance into an utterance queue that tells your browser what to speak. Start the speech utterance via the SpeechSynthesis.speak() method.
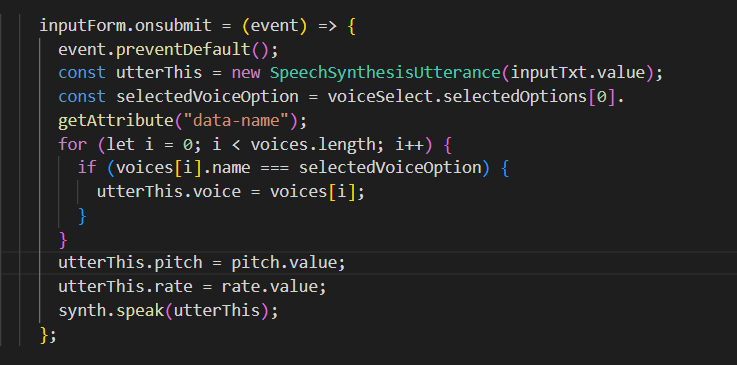
Speech Synthesis Utterance Interface
SpeechSynthesis Instance properties
- speechSynthesis.paused : A boolean value that returns true if the SpeechSynthesis object is in a paused state.
- speechSynthesis.pending : A boolean value that returns true if the utterance queue contains unspoken utterances.
- speechSynthesis.speaking : A boolean value that returns true if an utterance is currently in the process of being spoken.
SpeechSynthesis Instance methods
- SpeechSynthesis.cancel(): Removes all utterances from the utterance queue.
- SpeechSynthesis.getVoices(): Returns a list of SpeechSynthesisVoice objects representing all the available voices on the current device.
- SpeechSynthesis.pause(): Puts the SpeechSynthesis object into a paused state.
- SpeechSynthesis.resume(): Puts the SpeechSynthesis object into a non-paused state.
Advantage and User Experience
- Accessibility: Speech technology significantly enhances accessibility by providing an alternative mode of interaction for those facing challenges with traditional keyboard or mouse inputs. By integrating speech recognition and synthesis capabilities into web applications, developers can create more inclusive experiences for users with disabilities. It enhances the learning experience of students with disabilities, as they can engage with educational content using their voices, simplifying navigation, interaction, and engagement with the material.
- User-Friendly Interaction: Speech recognition software provides a simple way to get words into a document without having to be delayed in the process. It provides a way for the user to communicate with the user in a more natural manner. This is highly valuable in scenarios where typing is inconvenient.
- Efficiency: Using web speech technology can make things more convenient and faster which eventually boosts productivity. Speech-to-text conversion can significantly cut the time spent on data entry.
Challenges and Considerations
- Accuracy: The accuracy of speech recognition systems must be high to create any value. This is a very important factor to consider when choosing tools, especially for medical or legal needs. Achieving high accuracy in speech recognition across various accents and languages remains a challenge. Word error rate (WER) is a commonly used metric to measure the accuracy & performance of a voice recognition system. Developers need to consider the limitations of the technology and manage user expectations.
- Background Noise: When the system is exposed to the real world, there are a lot of background noises such as cross-talk, and environmental noise. Background noise can be a significant barrier in improving the audio quality. Developers must consider ways to filter out noise and account for various environmental disturbances.
- Data privacy and security: A voice recording of someone is used as their biometric data therefore, many people are reluctant to use voice tech since they think this makes them vulnerable to hackers and other security threats. Brands such as Google Home and Alexa collect voice data to improve the “accuracy” of their devices. Companies also use customer voice recordings gathered by voice assistants, to target relevant advertisements to their customers on their different platforms. These voice data can be sensitive and can raise privacy concerns. Companies must follow strict permissions policies and transparency for using customer voice data.
- Offline support: An Internet connection is necessary for the API to function. At the moment, the browser sends the input to its servers, which then returns the result. This limits the circumstances in which Web Speech API can be used.
Conclusion
Web Speech API has the ability to make it possible to communicate with disabled people. when it comes to voice assistance and control, the possibilities are endless. The area of Speech Technology has vast possibilities for enhancement and development in the future.
