
Power of Incremental Models in DBT: A Deep Dive
In the previous blog, we briefly introduced DBT (Data Build Tool) and the fundamental ways it could change how you analyze and transform your data. We discussed the basics, explored its main components, and established the basis for comprehending its capabilities.
DBT (Data Build Tool) is a remarkable data analytics tool that is becoming increasingly popular with both data engineers and analysts. In this blog article, we will look at incremental models, one of DBT’s key features, and see how they can help businesses streamline their data transformation techniques. We’ll provide you with a thorough knowledge of incremental models, present real-world examples with reference codes, and highlight how they could affect your data analytics process.
Understanding Incremental Models
In the context of DBT, incremental models are a means of streamlining data transformations by only processing data that has changed or been added since the prior run. This strategy guarantees that your analytics are always up to date while minimizing processing time and resource utilization. Traditional ETL (Extract, Transform, Load) pipelines frequently process every piece of data from scratch, which can take a lot of time and resources. On the other hand, incremental models just process the changes, leading to quicker and more effective transformations.
As incremental models transform and insert only the recent data, you should have at least one column with the following data types in your table: DateTime, timestamp, date, or int64.
The model compares the values of columns from source and target tables and filters the data that needs to be transformed, inserted, updated, or deleted.
You need to follow these conditions if you want your model to run incrementally:
- The model should be configured with materialized = ‘incremental’.
- The model should not run in full-refresh mode.
- The target table should be present in the database.
When to Use Incremental Models?
Incremental models are particularly useful when dealing with large datasets or frequent data updates. Here are some scenarios where incremental models shine:
- Daily Data Loads: If your organization receives daily data updates, using incremental models can prevent the need to reprocess all the data every day, saving valuable time and resources.
- Large Datasets: If you’re dealing with large datasets, processing them in their entirety can be resource-intensive and time-consuming. Incremental models allow you to update only the portions of the data that have changed, reducing the computational load significantly.
- Data Transformation Complexity: Assess the complexity of your data transformations. Incremental models can simplify data processing when the majority of your data remains unchanged, and only a subset needs transformation.
- Cost Optimization: Organisations operating in cloud environments often face escalating costs as data volumes grow. By implementing incremental models, you can optimize your resource utilization and reduce cloud infrastructure costs.
Now that we understand the concept and scenarios where incremental models are beneficial, let’s dive into implementing them in DBT.
DBT Incremental Append
Append strategy just inserts the new records in the target table. As it does not check if a record already exists in the target table, there are chances of duplicate records in the target table. So when duplicates are not the problem, append is the best strategy to use because processing cost is very low as we don’t need to scan the table to check duplicates.
Append Example
To demonstrate the use of the DBT append incremental strategy with a simple dataset, we’ll walk you through the process step by step. Let’s assume you have a source dataset called tv_series, containing tv series data and it creates a new table called append model.
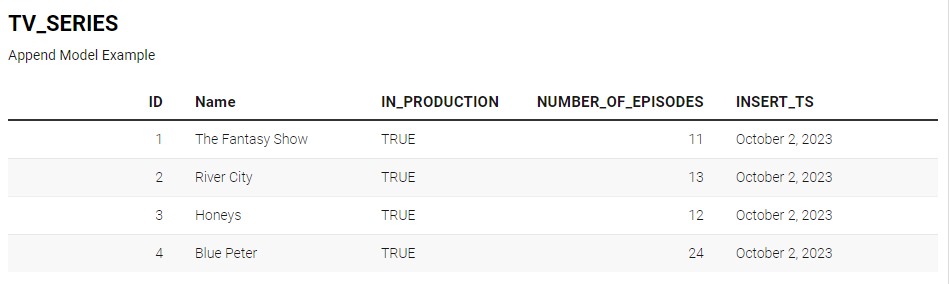
As mentioned earlier, the append incremental strategy is useful when you want to append new data from your source without worrying about duplicate records. In consideration of that, let’s add two new records to the source table having the same IDs and series name but with a different number of episodes.

Following the incremental run for the above data source using the append incremental approach, the resulting output might look something like this.
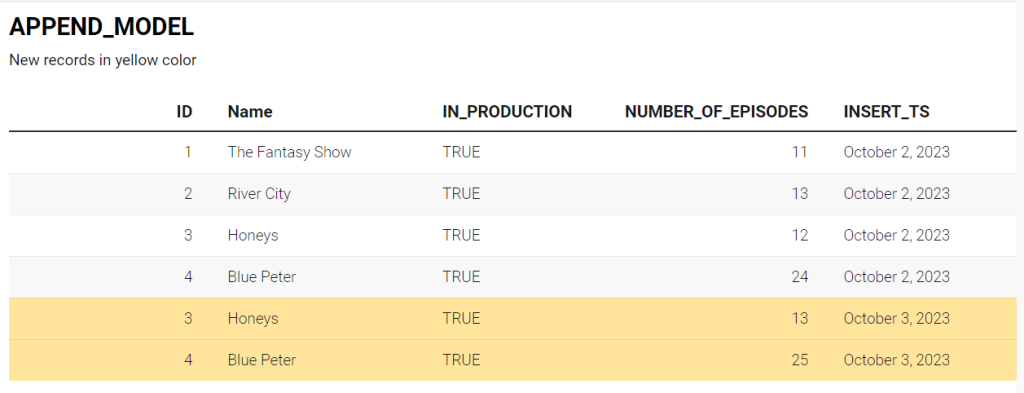
As it can be seen, a series that has been added in the source with a new number_of_episodes is now duplicated in the final table. Using the insert_ts field we have inserted only the most recent data. The append strategy can be implemented using the following DBT model.
{{config(
materialized='incremental',
incremental_strategy='append'
)}}
SELECT
ID,
NAME,
IN_PRODUCTION,
NUMBER_OF_EPISODES,
current_timestamp() as INSERT_TS
FROM
{{ ref ('tv_series')}} a
{% if is_incremental() %}
WHERE
a.insert_ts > (SELECT MAX(x.insert_ts) FROM {{ this }} x)
{% endif %}
Wrap valid SQL that filters for these rows in the is_incremental() macro to instruct dbt which rows it should change on an incremental run. The is_incremental() code will look for rows that have been added or updated since dbt last ran this model.
DBT Incremental Merge
Merge strategy updates the already existing records and inserts the new records in the target table. In the merge strategy, we create a unique key in the source and target table. We match the unique keys from both tables. If unique key matches for any record that record will be updated, so we will not have duplicate records. Records for which unique key does not match, those records will be inserted. If we don’t create a unique key in the merge strategy, it becomes an append strategy. The processing cost of using the merge strategy is very high as it has to scan the whole table to remove duplicates.
Merge example
Let’s follow the same dataset that we followed in our above example and implement the DBT merge strategy. Let’s assume you have a source dataset called tv_series, containing tv series data and it creates a new table called merge_model this time.
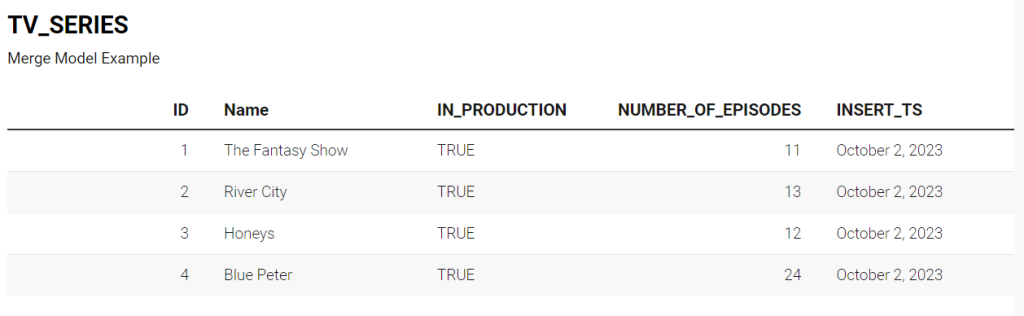
Unlike the append strategy, the merge strategy effectively addresses the issue of duplicate records by allowing you to define a unique key, which can consist of one or more columns. When this unique key already exists in the target table, the merge operation will update the existing record, preventing duplicates. However, if the records with that unique key do not exist, the merge operation will insert them.

Following the incremental run for the above data source using the merge incremental approach, the resulting output might look something like this.
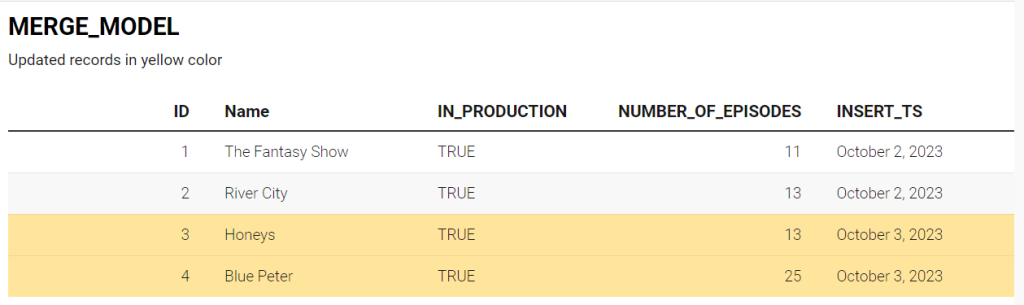
As it can be seen, a series that has been added in the source with a new number_of_episodes is now updated in the final table. Using the merge strategy we don’t need to worry about the duplicate records in the final table. In the insert_ts field, we have inserted only the most recent data. The merge strategy can be implemented using the following DBT model. Notice that we are using a unique key constraint in the config block of the model.
{{config(
materialized='incremental',
unique_key='id',
incremental_strategy='merge'
)}}
select
ID,
NAME,
IN_PRODUCTION,
NUMBER_OF_EPISODES
current_timestamp() asINSERT_TS
from {{ ref('tv_series')}} a
{% if is_incremental() %}
WHERE
a.insert_ts > (SELECT MAX(x.insert_ts) FROM {{ this }} x) -- this = same table
{% endif %}
Conclusion
The DBT incremental model is a powerful tool that processes new or updated records, eliminating the need for constant comprehensive model updates. This becomes particularly useful when dealing with large source tables that are time-consuming to run. The primary advantages of DBT incremental models are their ability to enhance performance and significantly reduce the run times of data models.
After delving into the details, you’ll gain a clear understanding of when to utilize incremental models and when it’s best to opt for other options. The decision is yours to make!
I hope you found this blog informative and engaging. Stay tuned for our next blog where we will explore more features of DBT, including macros and seeds, among others. Happy dbt-ing!
