
PDF Utilities using Python
Overview
PDF (Portable Document Format) stands out for it’s ability to preserve formatting across different devices and platforms. Whether for business reports, academic papers, or e-books, PDF has become a de-facto standard of document sharing in today’s world.
Python, a versatile and robust programming language, offers a suite of libraries that make working with PDFs not just feasible but powerful and reliable. Its simplicity and readability make it an excellent choice for both beginners and seasoned developers. When it comes to handling PDFs, Python’s capabilities extend far beyond basic operations, offering reliability and efficiency in even the most demanding scenarios.
Here are some reasons why Python stands out:
- Ease of Use: Python’s syntax is clean and easy to understand, making it accessible for anyone to start manipulating PDFs.
- Rich Ecosystem: Python boasts a plethora of libraries tailored for PDF operations, ensuring that you have the right tool for any job.
- Community Support: A large, active community means continuous improvements and abundant resources for troubleshooting and learning.
Use Cases
When it comes to working with PDFs, Python’s rich ecosystem of libraries offers a powerful toolkit to handle a wide variety of tasks. Whether you’re managing a large collection of documents, extracting critical data, or generating reports from scratch, these libraries provide robust solutions for both basic and complex operations. From manipulating and merging files to adding interactive elements and securing sensitive information, Python’s PDF libraries are versatile and efficient. Below is a comprehensive index of the operations you can perform using these tools, showcasing the breadth of possibilities.
- Creating a PDF
- Creating bills/ invoices like documents
- Creating graphical documents containing images and canvas
- Creating a document from an existing Word document
- Extracting texts/ images/ tables from a PDF
- Extract computerized texts from a PDF
- Extract humanly written text using OCR
- Extract images, and tables from a PDF
- Searching and extracting specific text patterns
- Extracting Embedded/ Attached files from a PDF
- Creating Interactive forms with Bookmarks and Annotations
- Joining/splitting PDF documents into one or many
- Compressing / Optimizing PDF for smaller file size
- Merging multiple documents to create watermarks
- Handling file privacy
- Password protecting a PDF document
- Adding digital signatures
- Redacting sensitive information
- Updating document metadata (author, title, subject, etc.)
Some Popular Libraries for handling PDF documents
There are numerous popular PDF libraries in Python, each developed with specific goals and functionalities in mind. These libraries are sorted by the number of features they support. Some libraries, like PyMuPDF and Spire.PDF, offer a wide array of features, including reading, writing, merging, splitting, and extracting content from PDFs, making them versatile for various tasks. Others, such as PyFPDF and Slate, are more lightweight and focus on specific operations like reading and text extraction. Depending on the use case, developers can choose a suitable library that best meets their needs, whether it’s a lightweight option for simple reading tasks or a comprehensive tool for more complex PDF manipulations.
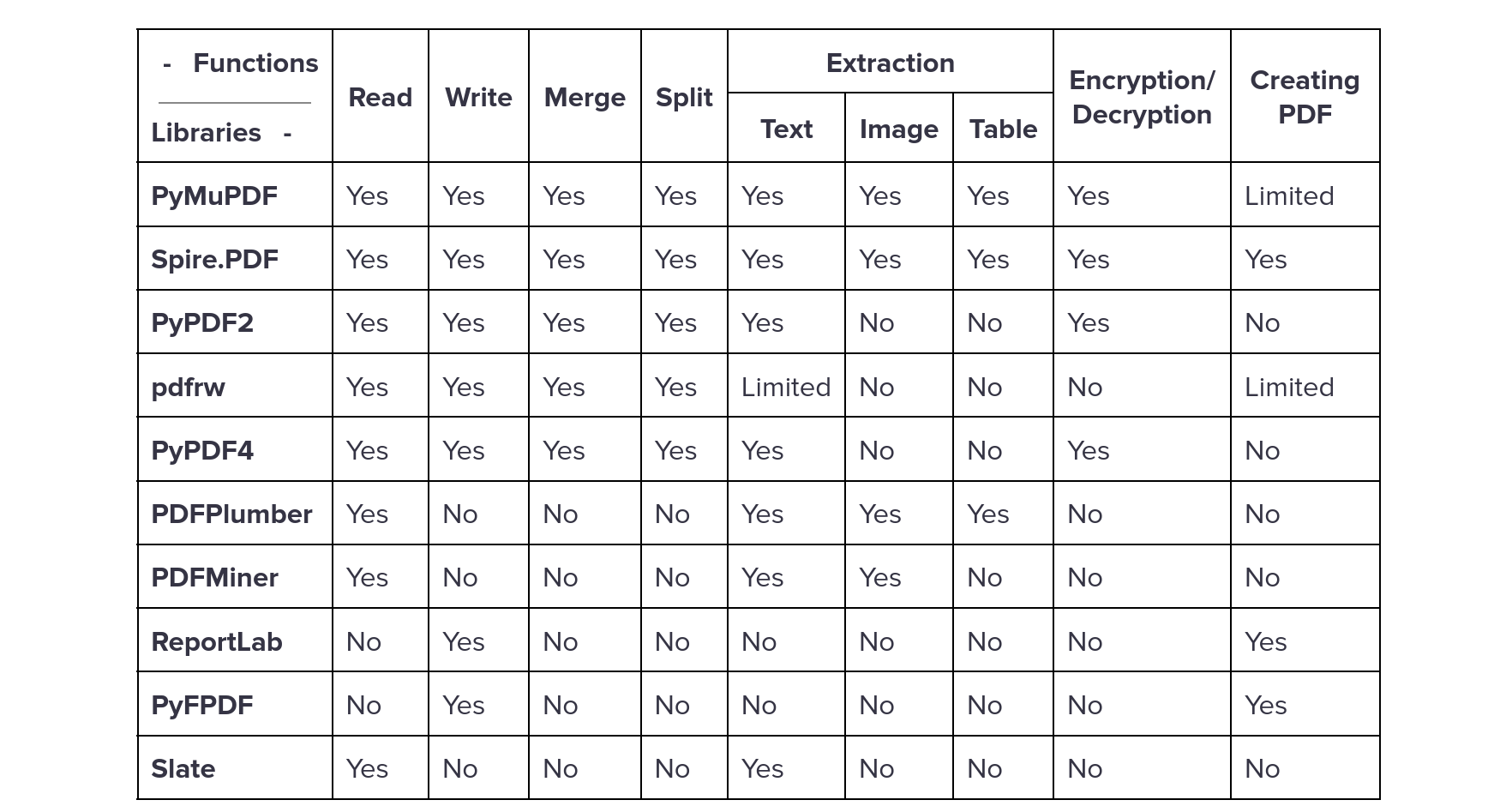
PDF Libraries Table
Challenges we tackled in our projects
- A U.S.-based insurance consulting firm needed to extract questions from various application forms provided by different insurance companies programmatically and reliably. By utilizing the mentioned PDF libraries, we were able to handle various edge cases and variations in PDF layouts to accomplish this task.
- A financial consulting firm required the extraction of QR codes from PDF invoices and the subsequent programmatic reading of these QR codes to generate reports. We utilized the image extraction features of these PDF libraries to achieve this objective.
Conclusion
Choosing the right library for a specific task is crucial when working with PDFs in Python. Each library offers unique strengths, catering to different needs and use cases. For simple tasks like reading or basic text extraction, lightweight libraries such as PyFPDF or Slate are ideal, offering straightforward solutions without the overhead of more complex features. On the other hand, for more demanding operations like creating, merging, or encrypting PDFs, comprehensive libraries like PyMuPDF or Spire.PDF provide the robust functionality required to handle intricate tasks efficiently.
By aligning your library choice with the specific requirements of your project, you can ensure optimal performance and ease of use. Whether you’re a beginner looking for an easy entry point or a seasoned developer tackling complex PDF manipulations, Python’s rich ecosystem of libraries has you covered, providing reliable and efficient tools for all your PDF-related needs.
