
Optimizing CI/CD Efficiency: Managing Long-Running Jobs in Jenkins for Better Resource Utilization

Jenkins
Introduction
In the Jenkins pipeline, long-running jobs can be a significant bottleneck, leading to resource inefficiencies and potentially delaying project timelines. Jenkins, a widely used automation server, offers powerful tools to manage and optimize these long-running tasks, ensuring that your CI/CD processes remain smooth and efficient. This blog will explore strategies and best practices for handling long-running jobs in Jenkins, focusing on optimizing resource utilization, improving job reliability, and minimizing downtime.
Objectives
- Efficient Job Execution: Use Jenkins Plugin/Features to run Jenkins jobs efficiently.
- Scalability: Automatically scale instances according to Job demand using EC2 Fleet .
- Cost Optimization: Reduce operational costs by leveraging Spot Instances.
The Problem: Performance Impact of Long-Running Jobs
Jenkins servers are designed to handle multiple jobs simultaneously, but when a job takes significantly longer than expected, it can monopolize server resources. This can lead to slower performance, delayed job execution, and even server instability if not managed properly. For organizations running large-scale CI/CD pipelines, the stakes are even higher, as performance bottlenecks can directly impact development cycles and delivery timelines. These jobs can strain your CI/CD infrastructure if not managed effectively, leading to issues like:
- Resource Contention: Long-running jobs can monopolize Jenkins agents, leading to delayed execution of other tasks.
- Job Failures: Extended runtimes increase the likelihood of encountering errors or interruptions, potentially leading to job failures.
- Pipeline Delays: Slow completion times can cascade through your pipeline, causing delays in subsequent stages.
Strategies for Managing Long-Running Jobs
Long-running jobs can be challenging to manage in Jenkins, as they can tie up resources, slow down other tasks, and potentially cause pipeline bottlenecks. However, by implementing a few strategic approaches, you can optimize your CI/CD pipeline and ensure these jobs are handled efficiently. Here are some key strategies:
1. Multi-Stage Execution
One of the most effective ways to reduce the impact of long-running jobs is by breaking them down into smaller, parallelizable tasks. Jenkins supports parallel execution within pipelines, allowing different parts of a job to run simultaneously. This approach can significantly decrease overall job completion time and free up resources more quickly.
Parallel Stages: Divide large tasks into smaller stages that can run concurrently within your Jenkins pipeline.
Distributed Builds: Utilize multiple Jenkins agents to distribute the workload, enabling different parts of the job to execute on different machines.
2. Checkpointing and Job Resumption
For jobs that might be interrupted or could fail midway, implementing checkpointing can be invaluable. Jenkins offers plugins, such as the “Checkpoint” plugin, that allow you to save the state of a job at various stages. If a job fails or is interrupted, it can be resumed from the last checkpoint rather than starting over, saving time and resources.
Stateful Jobs: Incorporate checkpoints at critical stages of your long-running jobs to save progress.
Job Resumption: Set up your pipelines to resume from the last successful checkpoint in case of a failure.
3. Resource Optimization
Preventing long-running jobs from monopolizing resources is essential for maintaining pipeline efficiency. Optimizing resource usage can ensure that other tasks aren’t delayed or impacted by a single job.
Node Labeling: Assign specific labels to nodes that are optimized for long-running tasks, ensuring these jobs run on the most suitable infrastructure.
Dynamic Scaling: Leverage cloud-based Jenkins agents that can scale dynamically according to demand, ensuring resources are only used when necessary.
4. Monitoring and Alerts
Establish robust monitoring and alerting mechanisms to keep track of long-running jobs. Jenkins offers various plugins, such as the “Prometheus” plugin, that integrate with monitoring tools, providing real-time insights into job performance. Alerts can be configured to notify teams of potential issues, enabling quick intervention.
Real-Time Monitoring: Implement monitoring tools to track resource usage, job duration, and agent performance.
Alerts and Notifications: Set up alerts to notify your team of any anomalies, such as jobs taking longer than expected or resource thresholds being exceeded.
Leveraging Jenkins Plugins/Features for Long-Running Jobs
Addressing the challenges posed by long-running jobs in Jenkins requires a combination of optimization techniques, infrastructure management, and strategic planning. The following strategies can help mitigate the impact of these jobs and improve the overall efficiency of your CI/CD pipeline:
1. Leverage EC2 Fleet for Dynamic Scaling
One of the most effective strategies for managing long-running jobs in Jenkins is utilizing Amazon EC2 Fleet. EC2 Fleet allows you to dynamically scale your Jenkins agents based on demand, ensuring that your infrastructure can handle both short and long-running tasks without bottlenecks.

ec2-fleet-plugin
- Dynamic Resource Allocation: EC2 Fleet integrates with the Jenkins EC2-Fleet plugin to automatically scale the number of agents up or down according to the workload. When long-running jobs are detected, additional instances are launched to handle the load, preventing delays in the pipeline.
- Spot Instances for Cost Efficiency: By using Spot Instances within your EC2 Fleet, you can significantly reduce operational costs. Spot Instances are typically available at a fraction of the price of On-Demand Instances, making them ideal for scaling large numbers of Jenkins agents, especially when running long jobs.
- Scaling Policies and Parameters: Configure the EC2 Fleet plugin with the following parameters to optimize your setup:
- Number of Executors: Set this to 1 or as per your requirement to control how many jobs can run concurrently on each agent.
- Max Idle Minutes before Scaledown: Set this to 1 minute or as per your requirement, ensuring that instances are scaled down quickly during idle periods to save costs.
- Minimum Cluster Size: Set this to 0 or as per your requirement, allowing the cluster to scale down to zero when no jobs are running.
- Maximum Cluster Size: Set this to 1 or as per your requirement, defining the maximum number of instances that can be provisioned to handle your jobs.
- Minimum Spare Size: Set this to 0 or as per your requirement, ensuring that no spare instances are kept running when they are not needed.
- Maximum Total Uses: Set this to -1 (default), allowing instances to be reused indefinitely unless other conditions trigger their termination.
- Instance Labeling: Use instance labeling to designate specific instances for long-running jobs. This helps isolate these jobs from others, allowing for better management and monitoring of resources dedicated to time-intensive tasks.
- Monitoring and Adjustments: Regularly monitor the performance and costs associated with your EC2 Fleet setup. Adjust the instance types, scaling limits, and other parameters to optimize both performance and expenses.
By leveraging EC2 Fleet with these settings, you can ensure that your Jenkins environment remains agile, responsive, and cost-effective, even when faced with the challenges of long-running jobs.
2. Parallel Execution
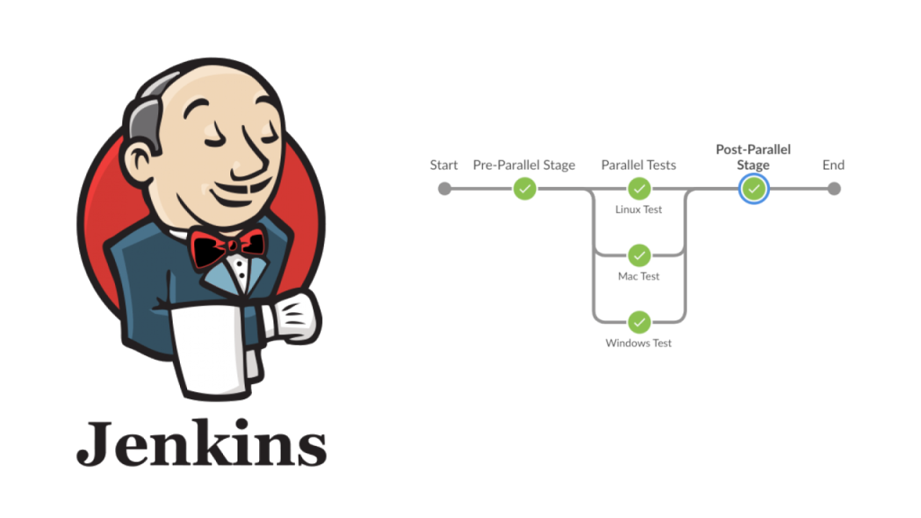
Parallel Job Execution
One of the most effective strategies to mitigate the impact of long-running jobs is by breaking them down into smaller, parallelizable tasks. Jenkins provides robust support for parallel execution within pipelines, enabling you to run multiple parts of a job simultaneously. This approach can significantly reduce overall job completion time, improve resource utilization, and accelerate your CI/CD pipeline.
- Parallel Stages: Instead of processing a large task sequentially, you can break it down into smaller stages that can run concurrently within a Jenkins pipeline. For example, if your job involves running a series of tests, you can divide these tests into groups that can be executed in parallel. By doing so, you not only speed up the testing process but also reduce the wait time for subsequent pipeline stages.
- Distributed Builds: Jenkins allows you to distribute the workload across multiple agents, enabling different parts of the job to execute on different machines simultaneously. This is particularly beneficial for large-scale builds or deployments that can be split into independent tasks. For instance, compiling different modules of a project on separate agents can significantly reduce build time. Additionally, by distributing the workload, you prevent a single agent from becoming a bottleneck, allowing other tasks to proceed without delay.
- Number of Executors: we can set a number of executors in Jenkins according to the CPU and Memory configured for our server, such that only that number of pipelines can run at a time.
3. Prometheus Plugin:
Provides metrics and monitoring for Jenkins jobs, enabling better tracking and alerting.
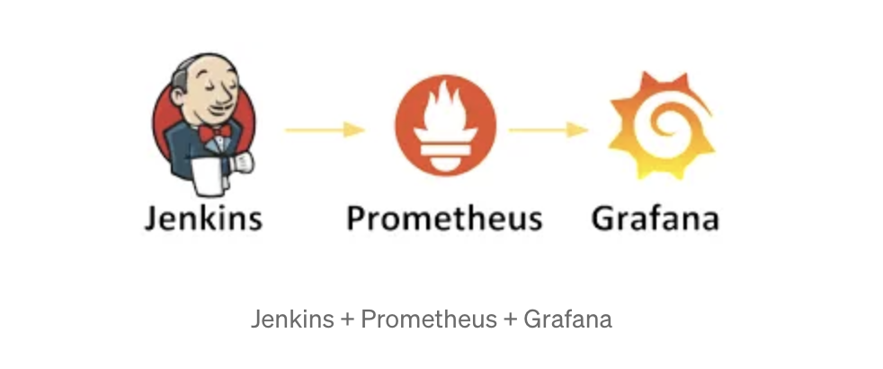
jenkins-prometheus
Here are a few expanded points for the Prometheus Plugin in Jenkins:
- Real-Time Metrics: Collects real-time metrics on job performance and Jenkins resource usage.
- Custom Dashboards: Integrates with Prometheus/Grafana to create custom monitoring dashboards for Jenkins.
- Alert Configuration: Allows setting up alerts for specific metrics like job failures or build durations.
- Improved Visibility: Enhances visibility into Jenkins operations through detailed monitoring.
- Scalability Insights: Provides insights into how Jenkins scales under different workloads.
- Efficiency Monitoring: Tracks resource consumption, helping identify inefficiencies in job execution.
Conclusion
Adopting these strategies will not only help in mitigating the challenges posed by long-running jobs but also enhance the overall efficiency of your Jenkins environment. Implementing dynamic scaling with EC2 Fleet, optimizing job execution through parallelism, and leveraging detailed monitoring with the Prometheus plugin will contribute to a more responsive, cost-effective, and high-performing CI/CD pipeline.


