
MySQL Perfomance Tuning
Introduction
MySQL is one of the most popular open-supply relational databases. As your application’s statistics grow, MySQL’s performance may be impacted by different factors, including database design, server configuration, and query performance. In this blog, we can talk about the various components of MySQL’s overall performance tuning and explore common situations to help you to optimize your MySQL database for the most suitable speed and performance.
Assume you’ve got a large e-commerce database. When someone attempts to fetch consumer-integrated or built-income-integrated, then he/she can face performance issues if the database queries are not optimized.
Debugging
a. Utilize Built-in Tools: Use some of MySQL’s built-in tools, like the Slow Query Log or Performance Schema, to identify queries that take longer to execute.
b. Monitor Query Metrics: Monitor the query execution time, query count, and other relevant metrics to pinpoint the problematic queries.
Inspection of Query Execution
a. Use EXPLAIN to advantage perception into how the MYSQL optimizer executes select statements. It helps you to recognize how MYSQL procedures your queries, inclusive of index usage and capacity overall performance bottlenecks such as complete table scans, inefficient index utilization, or complex joins
b. Example:
EXPLAIN SELECT * FROM users WHERE email = ‘user@example.com’;
Result
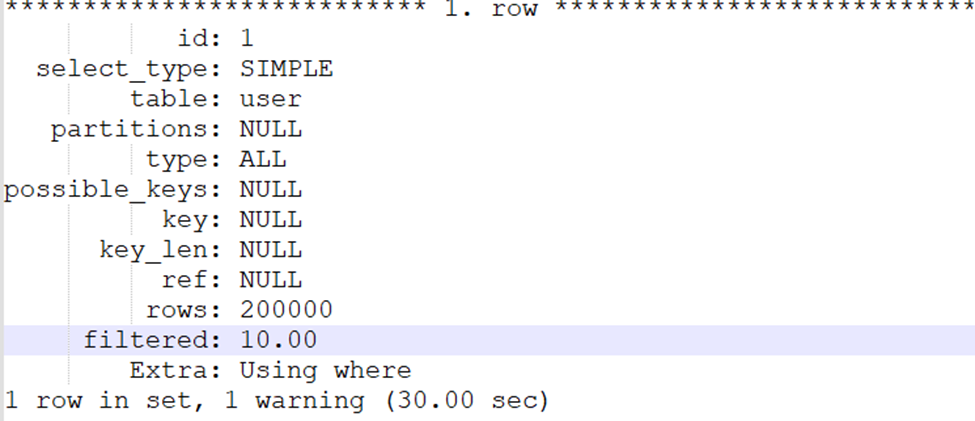
id: A unique identifier for each selected operation within the query.
select_type: The type of select operation. In this case, SIMPLE indicates a simple SELECT query.
partitions: The partitions being accessed (if applicable).
type: The join type or access method used. Here, the ref indicates a range scan using an index.
possible_keys: The indexes that could potentially be used (email in this case).
key: The index MySQL chooses to use (email in this case).
ref: The columns used for joining or filtering (const indicates a constant value).
rows: Estimated the number of rows that MySQL needs to examine.
filtered: The percentage of rows that are filtered out by the condition.
Extra: Additional information about the execution plan (Using index indicates that the query uses the index to satisfy the condition).
The above query is not optimized, so it takes around 30 sec to fetch records
Query Optimization
1. Indexing Strategy
a. Poorly optimized query
SELECT * FROM users WHERE email =’user@example.com’;
If the query is run without indexing, the database engine scans the entire “users” table to find the user with the specified email address. This can be very slow, especially in large tables.
b. Optimisation
CREATE INDEX idx_email ON users(email); SELECT * FROM users WHERE email = ‘user@example.com’;
2. Proper Use of JOINs
a. Poorly optimized query
SELECT * FROM customers, orders WHERE customers.id = orders.customer_id;
b. Optimized query using INNER JOIN
SELECT orders.*, customers.name FROM orders INNER JOIN customers ON orders.customer_id = customers.id;
In the first example, the query combines data from orders and customer tables without explicitly specifying how the tables are related. In the second example, an explicit join helps define the relationship between the two tables based on the mentioned columns. Consequently, it helps retrieve and present data as a unified result set.
3. Avoid select with *
a. Poorly optimized query
SELECT * FROM products WHERE id = 3;
b. Optimized query selecting specific columns
SELECT product_id, product_name, price FROM products WHERE category_id = 3;
Queries specifying needed columns are quite efficient than selecting ‘*’ queries.
4. IN vs JOINs
Avoid using the IN operator. The IN operator filters rows based on a list of values for a column. It is used with a subquery or list of literals.
a. Poorly optimized subquery
SELECT * FROM customers WHERE id IN (SELECT customer_id FROM orders GROUP BY customer_id HAVING COUNT(*) > 5);
b. Optimized query using JOIN
SELECT customers.* FROM customers INNER JOIN (SELECT customer_id FROM orders GROUP BY customer_id HAVING COUNT(*) > 5) AS loyal_customers ON customers.id = loyal_customers.customer_id; JOIN clause is used to explicitly define the relationship between the table and the subquery making the query more efficient.
5. Union vs. OR
Avoid using OR operator when multiple columns have indexing in the same table. Suppose there’s an index on the category and a separate index on the city column in the user table.
a. Poorly optimized query with OR
SELECT * FROM users WHERE category = ‘A’ OR city= ‘B’;
MySQL generally uses only one index per table in a query; which index should it use? If it uses the index on category, it would still have to do a table scan to find rows where the city is ‘B.’ If it uses the index on the city, it would have to do a table scan for rows where the category is ‘A’.
b. Optimized query using UNION
SELECT * FROM users WHERE category = ‘A’ UNION SELECT * FROM users WHERE city= ‘B’;
The UNION operator is used to combine the result units of two or extra pick-out queries that can use the index for its search into a single result set. The columns in the result units need to have the same record kinds and be in equal order. The UNION operator gets rid of replica rows from the mixed result set.
6. Use EXISTS for Existence Check
a. Poorly optimized query
SELECT COUNT(*) FROM subscribers WHERE email = ‘subscriber@example.com’;
b. Optimized query using EXISTS
SELECT EXISTS(SELECT 1 FROM subscribers WHERE email = ‘subscriber@example.com’);
The EXISTS operator stops evaluating as soon as it finds a matching row, whereas the COUNT function needs to scan the entire result set to determine
7. Use Limit
a. Poorly optimized query
SELECT * FROM orders ORDER BY order_number DESC;
When you execute a query without the LIMIT clause, the query retrieves all rows from the specified table. This can result in a large result set, especially if the table contains a significant number of rows.
b. Optimized query with a reasonable limit
SELECT * FROM orders ORDER BY order_number DESC LIMIT 10;
Including the LIMIT clause in your query Improves performance, as you’re only retrieving a limited number of rows.
8. Memory Allocation
If all the above optimizations are done, and you still face some performance issues, then you can check and increase the memory size for the properties below.
9. InnoDB Buffer Pool
Increase InnoDB buffer pool size into configuration file- my.cnf or my.ini as per database requirements. The InnoDB Buffer Pool caches data and index pages from InnoDB tables in memory. It improves read performance by reducing the need to fetch data from disk for frequently accessed pages.
innodb_buffer_pool_size = 4G
10. Key Buffer Size
Configure Key Buffer Size as per database requirement into configuration file- my.cnf or my.ini. The Key Buffer Size, also known as the key cache, is used to cache index blocks for MyISAM tables. It’s used to improve read performance for queries that rely on indexes.
key_buffer_size = 256M
Choose Appropriate Storage Engines
MySQL helps multiple storage engines (e.g. InnoDB, MyISAM). Pick the proper one primarily based on your use case.
a. InnoDB: Suitable for most applications due to its ACID compliance, transaction support, and row-level locking.
b. MyISAM: This may be suitable for read-heavy, non-transactional workloads.
Table Optimization
Use the ANALYZE TABLE and OPTIMIZE TABLE statements to maintain optimal table performance by updating statistics and reclaiming fragmented space.
Analyze and optimize a table.
ANALYZE TABLE user;
When you execute this statement, MySQL will analyze the distribution of data within the users table, update index statistics, and store this information for query optimization. This process helps the query optimizer estimate the most efficient way to execute queries against the table.

OPTIMIZE TABLE user;
The Optimization process will create a temporary copy of the original table. The function replaces the original table with the optimized table once the operation is done, renaming it to the original.

For more details, refer to this — MySQL 8.0 Reference Manual :: 13.7.3.4 OPTIMIZE TABLE Statement
1. Choose appropriate information kinds
a. Use the Smallest statistics type possible
Pick out the smallest data type to accommodate your information without sacrificing accuracy. For instance, if you’re storing a range between 0 and 255, using the TINYINT records type (1 byte) is greater green than using an INT (4 bytes).
b. Avoid To Use Generic Types
Avoid using frequent information types like VARCHAR(255) for all string information. Choose data types that constitute the nature of your statistics, such as VARCHAR, TEXT, or ENUM.
c. Use Integer sorts for complete Numbers
For entire numbers, use integer statistics types- TINYINT, SMALLINT, INT, BIGINT
d. Use Floating-factor types for Decimal Numbers
For decimal or floating-point numbers, use the appropriate floating-point records kinds like FLOAT or DOUBLE.
e. Use Date and Time types for Temporal records
Use date and time statistics types for storing temporal information like DATE, TIME, DATETIME, TIMESTAMP
f. Use ENUM or SET for fixed cost Lists
If you have a set of feasible values for a column, do not forget to use ENUM or SET data types. This ensures information integrity and saves area compared to storing strings.
g. Use BLOB kinds for big Binary statistics
Use BLOB (Binary large object) record types like BINARY, VARBINARY, BLOB, or LONGBLOB for storing massive binary statistics like pics, audio, or files.
h. Use JSON information type for JSON information
If you’re storing JSON statistics, use the JSON facts type in MySQL 5.7. This allows for efficient garage and manipulation of JSON files.
i. Avoid To Store Computed Values
Avoid storing computed or derived values that can be calculated using square queries. Alternatively, calculate these values while needed.
2. Use Primary Keys
The primary keys uniquely identify each record (row) in a table. They are essential in maintaining data integrity, enforcing uniqueness, and enabling efficient data retrieval.
ALTER TABLE your_table ADD PRIMARY KEY (id);
Storage Considerations
a. Use SSDs (Solid-State Drives): for quick data access, low latency, fast Random Access and parallelism.
b. Disk Partitioning: Disk partitioning is a database optimization technique that involves dividing a large table into smaller, more manageable pieces called partitions. Each partition is stored separately on the disk and can be managed individually.
MySQL supports several types of partitioning:
a. Range Partitioning: Divides the data into partitions based on a specified range of values from a column. It is useful when you have data that can be logically divided into distinct ranges, like time periods
b. List Partitioning: Divides the data into partitions based on specified lists of values from a column. This is suitable for cases where data can be categorized into discrete sets.
c. Hash Partitioning: Distributes data among partitions based on a hash function applied to a column’s value. This can provide more uniform distribution, but partition keys aren’t based on the data’s nature.
d. Key Partitioning: Similar to hash partitioning, but the partitioning function uses column values directly as keys. It is useful for scenarios where you want to partition data based on specific column value
e. Data Compression: Enable MySQL’s built-in table compression (InnoDB) to reduce storage requirements and improve I/O performance. However, be mindful of the trade-off with CPU usage.
3. Regular Maintenance
Perform routine maintenance tasks such as optimizing tables, repairing corrupted tables, and monitoring disk space usage to prevent issues that can impact performance etc.
Query Cache
Enable the query cache for caching SELECT query results. However, be cautious with this in highly dynamic databases. The query cache works well for static or infrequently changing data. The cache might become less effective in highly dynamic databases where data changes frequently due to the constant need for cache invalidation and refreshing.
Example
Update the below fields into the configuration file- my.cnf or my.ini
query_cache_type = 1 query_cache_size = 256M
Connection Management
Adjust table and thread settings based on the configuration file- my.cnf or my.ini on your workload.
Update below fields-
table_open_cache = 2000
max_connections = 1000
Scaling Strategies
a. Horizontal Scaling (Sharding): Horizontal scaling involves distributing data across multiple servers or nodes. It’s an effective strategy for read-intensive workloads.
b. Replication: MySQL replication involves maintaining multiple copies of your database. It’s beneficial for both read scalability and high availability.
DB Partitioning:
Partition large tables to improve manageability and performance.
— Partitioning a table by a range
CREATE TABLE users ( user_id INT PRIMARY KEY, username VARCHAR(50), email VARCHAR(255) ) PARTITION BY HASH(user_id) PARTITIONS 8;
Caching: Enforce caching mechanisms to lessen the weight to your database.
Content Delivery Network (CDN): Offload static assets like images, videos, and scripts to a CDN to reduce the load on your database and improve content delivery speed.
Application-Level Optimization: Optimize your application code to minimize the number of queries and improve efficiency.
Load Balancing: Implement load balancers to distribute traffic across multiple database servers or nodes evenly
Sharding Proxy: Use a sharding proxy tool to automate data distribution across shards and manage communication between your application and databases.
Data Archiving
Archive old or infrequently accessed data to separate tables or storage.
Move old data to an archive table-
INSERT INTO archived_order SELECT * FROM sales WHERE order_date < ‘2020–01–01’; DELETE FROM sales WHERE order_date < ‘2020–01–01’;
Some Profiling and Monitoring Tools
a. MySQL Workbench: MySQL Workbench offers a graphical interface for database design, SQL development, and administration. It includes tools for performance tuning, query profiling, and visually explaining plans.
b. New Relic: New Relic offers application performance monitoring (APM) solutions that can monitor and provide insights into the performance of your MySQL database as part of your overall application stack.
c. Datadog: Datadog is a monitoring and analytics platform that can help you monitor, visualize, and analyze MySQL performance metrics.
Conclusion
MySQL performance tuning is a continuous process that involves optimizing queries, indexing, memory usage, storage strategies, and more. Understanding your application’s specific needs and the underlying MySQL features is essential for achieving optimal performance. Regular monitoring, profiling, and adjustments based on changing requirements will ensure your MySQL database operates efficiently. For More details please refer — MySQL 8.0 Reference Manual :: 8 Optimization.


