
Mastering Redshift to SQL Server Data Migration with SSIS: Challenges, Solutions, and Best Practices
Businesses utilize SQL Server Integration Services (SSIS) for transferring or merging data between Amazon Redshift and SQL Server. SSIS provides a robust ETL (Extract, Transform, and Load) Infrastructure for managing these migrations, ensuring data is accurately transferred and appended to existing datasets in SQL Server. Extracting data from Redshift is simplified by SSIS, which makes use of ADO.NET or Amazon Redshift ODBC connectors. Post-extraction, data modifications are implemented to ensure compatibility between the relational format of SQL Server and the columnar data structure of Redshift. Managing differences in data types, indexing techniques, and schema across the two platforms is crucial. Once the conversion is completed, the data can be incorporated into existing SQL Server tables, achieved by defining how the extracted data will be loaded into SQL Server tables through the SSIS “Data Flow” task.
Handling Massive Data Volumes Efficiently
In order to store mammoth data, ranging from millions to billions of records, on a large scale is the primary use case for Redshift. Migrating large datasets to SQL Server without proper handling may strain system resources and cause delays. The challenge lies in efficiently extracting, transferring, and loading large volumes of data without compromising system performance, transferring, and loading these substantial volumes without degrading system performance is the challenge.
The following are some solutions:
• Utilize data partitioning to process the data in smaller portions rather than all at once, dividing it into smaller batches or partitions based on date ranges or IDs.
• Take advantage of SSIS’s bulk insert features to swiftly load substantial volumes of data into SQL Server.
• Modify the sizes of the SSIS Data Flow buffers to maximize memory use and minimize the amount of I/O operations for buffer tuning.
Dealing with Data Type Differences
When migrating from Redshift to SQL Server, there may be incompatibilities due to the differing data types. For instance, Redshift’s DOUBLE PRECISION does not align with SQL Server’s FLOAT, and Redshift’s VARCHAR allows for longer lengths compared to SQL Server.
To address these issues:
- The first step is to create a detailed mapping plan for incompatible data types and use SSIS data conversion transformations to handle mismatches.
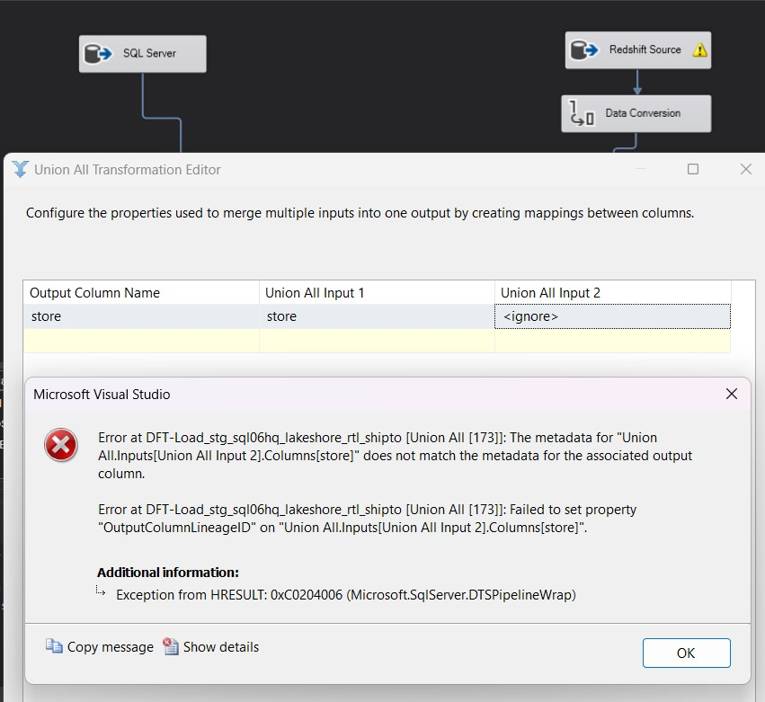
- Prior to incorporating complex data types such as ARRAY and SUPER into SQL Server, it may be necessary at times to utilize custom scripts to transform or flatten them. Here is an example, let’s assume there is a data type DT_NTEXT (Unicode Text Stream) with a length of 50 in Redshift that does not correspond to a column of DTSTR with a length of 50 in SQL Server due to the disparity in data types.
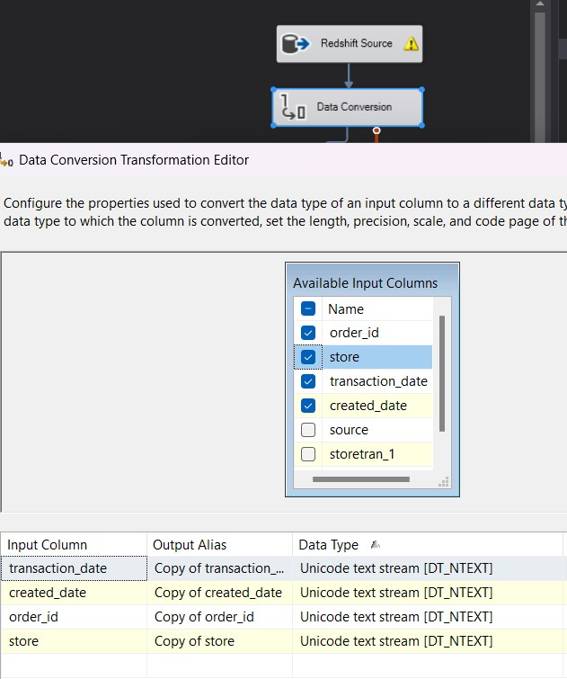
Even when utilizing the “Data Conversion” tool, SSIS does not allow a direct conversion.
A two-step conversion process is necessary to achieve the intended outcome:
- The conversion of DT_NTEXT (Unicode Text Stream) to DTWSTR (Unicode String).
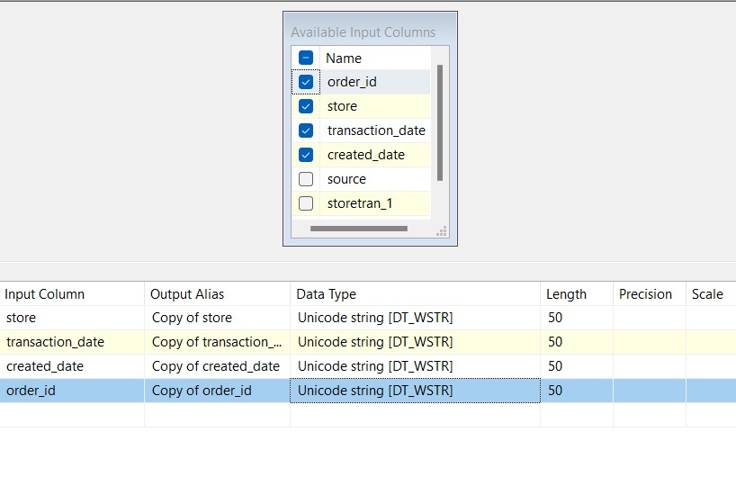
2. Subsequently, the conversion of DTWSTR to DTSTR with the appropriate length to align with the SQL Server data type.
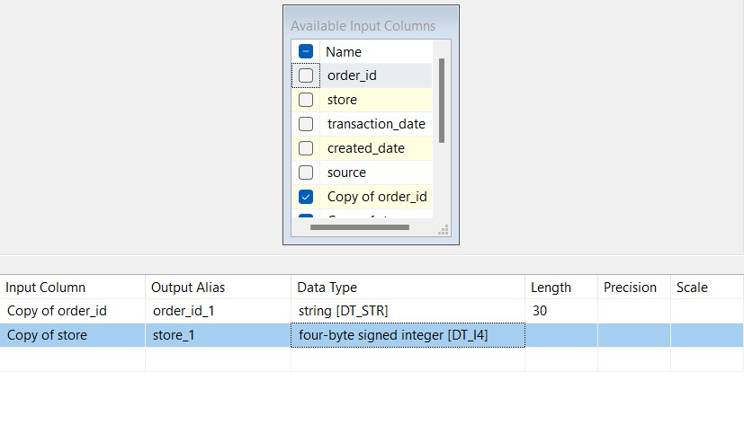
3. The resulting output can then be appended to the SQL Server column with no complications.
Data Transformation Complexities
When transferring data between Redshift and SQL Server, reorganization is often necessary due to the differing data storage formats used. For example, Redshift stores data in a columnar structure, while SQL Server uses a row-based approach. Additional modifications may also be required, like:
• Flattening complex data structures: Data structures like arrays or nested objects stored in Redshift may need to be flattened before appending them to SQL Server tables.
• Converting dates and times: Redshift handles timestamps and time zones differently from SQL Server, and improper conversion could lead to inconsistent data.
• Normalization and de-normalization: To adapt Redshift-retrieved data to the destination database structure, normalization or de-normalization may be necessary, depending on the SQL Server schema.
In some instances, aligning the SQL Server column data type with the Redshift column may be challenging and involve multiple data conversion steps. Consequently, the target table’s DDL in SQL Server will need adjustments.
ETL Management Tips for Redshift to SQL Server Migration
Data migrations encounter a significant performance challenge. Ineffective SSIS packages can result in prolonged loading times and increased utilization of resources. Performance issues typically stem from the following sources:
• Retrieving data from the source system may be sluggish, particularly when dealing with complex transformations in Redshift queries. It is essential to optimize queries and effectively utilize Redshift distribution keys for efficient data extraction.
• To boost performance, it is critical to optimize SSIS Data Flow components by adjusting buffer sizes, maximizing parallel execution, and reducing unnecessary transformations in the pipeline.
• Bottlenecks may arise in the target system, especially with SQL Server, if indexes, partitions, or storage are not optimized. Temporarily disabling non-essential indexes during the migration process can enhance insertion speed.
Dealing with Legacy Systems
When integrating Redshift data with legacy systems in SQL Server during migration, the challenge becomes more complex. Outdated schemas, obsolete data formats, or incompatible business logic may be utilized by legacy systems. To address these issues, the following steps need to be taken:
- Schema alignment: The legacy SQL Server schema must be updated or modified to accommodate the incoming Redshift data.
- Data cleaning and transformation: Legacy systems may possess inconsistent data or deprecated data types that require transformation to align with modern Redshift data formats.
- Testing and validation: It is important to thoroughly test the migration on a smaller subset of data to ensure the correct integration of legacy system data with new Redshift data.
Ensuring Data Integrity and Consistency
When undergoing migrations, it is vital to prioritize data integrity. The migration of data from Redshift to SQL Server requires careful attention to maintaining referential integrity, managing null values, and ensuring the consistency of primary and foreign key relationships, which can be quite intricate. Important factors to consider are:
- Data validation: Utilize SSIS’s data validation tasks to verify data consistency before and after the migration, ensuring that no records are lost or corrupted. E.g. mapping incompatible types like DOUBLE PRECISION in Redshift to FLOAT in SQL Server.
- Duplicate handling: Employ de-duplication techniques to thwart the occurrence of duplicate data in the destination SQL Server.
- Transaction management: Guarantee that data is either completely migrated or rolled back in the event of a failure to prevent incomplete migrations.
Managing ETL (Extract, Transform, and Load) Processes
To successfully manage the extensive ETL process during a large-scale migration, it is crucial to effectively coordinate the following tasks:
- Scheduling Jobs: When migrating incrementally, it is important to schedule ETL jobs to run during low-traffic periods in order to minimize resource contention.
- Error Handling and Logging: It is essential to set up error handling and logging appropriately to promptly capture and resolve issues during the ETL process. SSIS provides event handlers and built-in logging for tracking package execution.
- Testing and Rollback Plans: It’s always recommended to conduct the migration testing on smaller datasets and have a well-defined rollback plan in place to address any issues that may arise during the final migration.
- Data Partitioning: Partitioning data can greatly increase ETL performance for large-scale migrations by dividing the burden among several processing threads. Partitioned processing is possible with SSIS, allowing for the parallel migration of particular data subsets. This is especially helpful for large tables since it guarantees faster data movement and efficient resource consumption when partitioning by date or key values.
Examples: Partition data by date ranges (e.g., daily or monthly partitions) or by customer IDs to allow for efficient parallel processing.
Buffer Size Adjustments: Memory buffers are used by SSIS to transfer data across the ETL pipeline. Buffer sizes can be optimally adjusted to maximize memory use and minimize data transmission times.
- Default Buffers: SSIS utilizes pre-set buffer sizes, such as 10,000 rows or roughly 10 MB per buffer, but you can change these numbers to optimize memory usage for larger datasets. The ETL process can be accelerated by increasing buffer size or row count, which can decrease the amount of I/O operations.
- Tuning Buffer Settings: Based on the amount of memory that is available and the size of each row in the dataset, set the DefaultBufferMaxRows and DefaultBufferSize properties. It’s crucial to test several configurations in order to determine the optimal ratio of memory utilization to performance.
By addressing these challenges with the appropriate strategies and adhering to best practices, a more seamless and dependable data migration from Redshift to SQL Server can be achieved. Enable faster data-driven decision-making now! Talk To Our Experts.
