
Mastering Data Modeling
As you progress in your journey from business intelligence (BI) development toward data engineering or analytics engineering, one of the core skills you need to focus on is data modeling. Data modeling is the foundation for any data architecture—whether you are building databases, designing ETL pipelines, or creating data warehouses. Without a solid understanding of data modeling principles, you risk inefficiencies, poor performance, and data inconsistencies that can undermine the entire data process.
In this article, I will delve into the importance of data modeling, the different types of data models, and the best practices that will set you up for success as you move forward in your career.
So, what Is Data Modeling?
Data modeling is the process of creating a visual representation of a data system, outlining how data is structured, stored, and related to one another. It’s essentially a blueprint for building a database, ensuring that data is organized in a way that supports efficient storage, retrieval, and use.
For a data engineer, data modeling helps in building data architectures that are scalable, maintainable, and optimized for performance. It helps you ensure that the data you work with is clean, well-organized, and ready for analysis or further processing.
Why Data Modeling Is Crucial in Data Engineering?
As a data engineer, you will be responsible for designing systems that handle vast amounts of data. If the data is poorly modelled, you may encounter challenges such as slow query performance, redundancy, and data integrity issues. Data modeling allows you to:
1. Optimize Performance: Well-structured data models ensure that queries run efficiently, especially when working with large datasets.
2. Ensure Data Consistency: Properly modeled data avoids duplication and inconsistencies, ensuring a single source of truth across the organization.
3. Enhance Data Quality: A good model enforces constraints and rules that ensure the accuracy and reliability of your data.
4. Facilitate Scalability: As data volumes grow, a solid data model can handle increased demand without performance degradation.
5. Support Collaboration: Clear and well-documented data models make it easier for teams to collaborate, ensuring everyone understands the data’s structure and relationships.
Types of Data Models
Data modeling can be broken down into three main types, each serving a different purpose in the data architecture process. As a data engineer, we need to understand all three:
1. Conceptual Data Models:
– These are high-level models that define what the data is and how different entities relate to each other.
– They are used to communicate with stakeholders, outlining the scope and structure of the data without going into technical details.
2. Logical Data Models:
– These models go deeper into the details, defining the structure of the data, but without considering how it will be physically implemented.
– This step helps ensure that the data structure supports the required business logic.
3. Physical Data Models:
– Physical models translate the logical model into a technical implementation, considering the database platform (e.g., Snowflake, PostgreSQL) and optimizing for performance.
– In this phase, you define tables, columns, data types, indexes, partitioning, and any necessary constraints or relationships.
Let’s use an example of a movie ticket booking system to illustrate the concepts of data modeling. We will design the data model for a system that stores information about movies, theaters, customers, and bookings.
Step 1. Conceptual Model
- Movie: Represents the details of movies, such as title, genre, and release date.
- Theater: Represents the theaters where the movies are shown, including details like name and location.
- Customer: Represents the users who are booking the tickets.
- Booking: Represents the transaction of booking a ticket, including the customer, movie, and showtime.
Step 2. Logical Data Model
We can now move to a logical data model, where we identify the attributes and relationships between these entities. Here is the logical model with entities and their attributes:
- Movie: movie_id (Primary Key), title, show_time, release_date, location, description
- Cinema: cinema_id (Primary Key), cinema_name, cinema_location
- Customer: customer_id (Primary Key), name, email,number, age
- Transaction: trans_no (Primary Key), movie_id (Foreign Key), theater_id` (Foreign Key), customer_id (Foreign Key), resv_id
Below is a simple ER diagram representing the relationships between these entities.
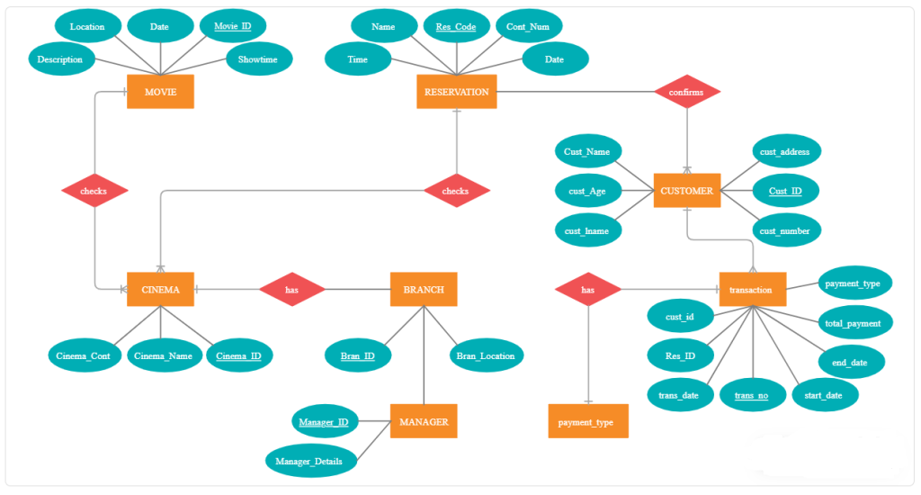
https://creately.com/diagram/example/hxpl8x6f/er-diagram-for-online-booking-cinema
This diagram helps clarify how movies, theaters, customers, and bookings are connected in a database structure, making it easier to understand the flow of data within the system.
Step 3. Physical Data Model
Once the logical model is defined, the next step is to map it to a physical data model—this is where specific data types and constraints are added, depending on the database technology being used.
For example:
– `movie_id`, `theater_id`, `customer_id`, `booking_id`: Integer (Primary Key)
– `title`: VARCHAR(255)
– `email`: VARCHAR(100)
– `show_time`: DATETIME
This combination of a practical example and the ER diagram provides a clearer picture of how data modeling works in real-world scenarios
Key Data Modeling Techniques in Data Engineering
1. Entity-Relationship Diagrams (ERD):
– ER diagrams are commonly used to visualize the relationships between entities (tables) in a database. These diagrams help you see how different entities (like Customers, Orders, Products) are related.
– As a data engineer, building ER diagrams during the design phase ensures a clear, logical structure before moving to physical implementation.
2. Normalization:
– Normalization is a technique to reduce redundancy and improve data integrity by dividing larger tables into smaller, related tables. This prevents data anomalies and reduces the amount of space required.
– Data engineers often normalize data up to the third normal form (3NF) to balance performance and data integrity.
3. Denormalization:
– Sometimes, performance needs require denormalizing data—merging tables back together for faster querying, especially in read-heavy environments like data warehouses.
– Denormalization introduces some redundancy but enhances query performance, particularly in OLAP (Online Analytical Processing) systems.
4. Star Schema vs. Snowflake Schema:
– These are two common database schema designs used in data warehousing.
– Star Schema: Simple and widely used, where fact tables (e.g., sales data) are surrounded by dimension tables (e.g., products, time, customers). This design is optimized for querying.
– Snowflake Schema: A more normalized form of the star schema, where dimension tables are further divided into related tables, reducing redundancy but potentially making queries more complex.
– As a data engineer, knowing when to use each schema type can make or break the performance of your data warehouse.
5. Dimensional Modeling:
– Dimensional modeling, often used in data warehouses, is the process of designing a fact and dimension structure that optimizes data retrieval.
– The fact table stores quantitative data (e.g., sales), while dimension tablesmstore descriptive attributes (e.g., customer, product). This model supports fast querying and analysis.
Best Practices in Data Modeling
1. Start Simple, Scale Later: Begin with a basic model that captures core business requirements. As the project grows, you can iterate on your model, adding complexity as needed.
2. Prioritize Performance: Think about the types of queries that will be run against your data. Design indexes, partitions, and relationships to optimize for those queries
3. Maintain Data Integrity: Always enforce data integrity with constraints (like primary keys, foreign keys) to prevent data corruption. This is especially important when multiple teams or systems rely on the same data.
4. Document Your Models: Ensure that your models are well-documented so that other engineers, analysts, and stakeholders can understand them. Clear documentation aids collaboration and troubleshooting.
5. Test Your Models: Before deploying your data model into production, test it thoroughly to ensure that it meets performance expectations, handles expected volumes of data, and aligns with business needs.
Tools to Get Started with Data Modeling
There are a range of tools at your disposal for data modeling. Some popular ones include:
– ER/Studio and IBM InfoSphere Data Architect: For complex enterprise environments.
– Microsoft Visi/darw.io: A simple yet effective tool for creating ER diagrams.
– dbt (data build tool): A modern tool for data transformation and modeling, particularly suited for data warehouses.
– SQL Server Management Studio (SSMS): If you’re working with SQL Server, SSMS has built-in tools for designing databases and building models.
Data modeling serves as the foundation for creating robust data pipelines and warehouses. The models you create will directly impact the performance of your systems, the quality of your data, and ultimately, the insights derived from it. Enable faster data-driven decision making now! Contact TO THE NEW.
