
How to Develop a RAG-Based Search System and Connect It to Drupal CMS
Introduction
In today’s information-driven world, delivering precise and contextually relevant search results is a critical challenge. This is where RAG (Retrieval-Augmented Generation) systems shine, combining the power of retrieval-based approaches with advanced generation models to enhance search accuracy and relevance.
In this blog, we’ll explore how to build a robust RAG-based search system using a Vector Database—a cutting-edge technology designed for handling high-dimensional data like embeddings from machine learning models. We’ll also demonstrate how to integrate this advanced search system seamlessly with Drupal CMS, a popular content management platform, ensuring a smooth user experience for both developers and end-users.
By the end of this guide, you’ll gain insights into:
- The fundamentals of RAG-based search systems and their benefits.
- How vector databases work and why they are ideal for RAG.
- Step-by-step integration of a RAG system with Drupal CMS to optimize content discovery.
What is a RAG System?
A Retrieval-Augmented Generation (RAG) system uses two main components:
- Retrieval Component: Fetches relevant documents or data from a dataset based on a query.
- Generation Component: Uses the retrieved documents to generate a response that is contextually accurate and relevant.
Why Use Qdrant?
Qdrant is an open-source vector database designed for real-time search and scalable applications. It’s optimized for handling large-scale data with high performance and offers features like:
- High-speed vector similarity search
- Scalability and distribution
- Advanced filtering and querying capabilities
Integrating Qdrant with a RAG System:
Step 1: Setting Up Qdrant
- Installation: Follow the Qdrant installation guide to set up Qdrant on your server.
- Configuration: Configure Qdrant based on your requirements, such as the number of shards and replicas for distributed setups.
Step 2: Prepare Your Data
To make your RAG system accessible, you can wrap its functionality in a Flask-based REST API. Flask is lightweight, easy to use, and ideal for deploying APIs.
API Structure
We’ll create two endpoints:
- Feed API: Accepts data, generates embeddings, and uploads them to Qdrant.
- Ask API: Accepts a user query, retrieves relevant context from Qdrant, and returns an AI-generated response.
Here’s how you can implement the Flask API (main.py):
from fastapi import FastAPI, Body, HTTPException
from pydantic import BaseModel, ValidationError
from fastapi import FastAPI, Request
import logging
from vector_db_manager import QdrantManager
from config import Config
import numpy as np
from knowledge_graph import neo4j
from data_chunk_manager import DataChunkManager
logging.basicConfig(level=logging.DEBUG)
app = FastAPI()
app_logger = logging.getLogger(__name__)
# function to chunk the data
def add_docs(
data: str,
):
chunk_manager = DataChunkManager()
document = chunk_manager.create_document([data])
embeddings = chunk_manager.generate_embeddings(document)
embeddings_array = np.array(embeddings)
embeddings_shape = embeddings_array.shape
vector_size = embeddings_shape[1]
if vector_size > 0 :
qdrant_manager = QdrantManager(collection_name=Config.collection_name, vector_size=vector_size)
doc_uuids = qdrant_manager.upload_documents(embeddings, document)
else :
app_logger.logger.info("Unable to create the embeddings. The embeddings array is empty or malformed.")
return doc_uuids
def find_docs(query):
chunk_manager = DataChunkManager()
query_embeddings = chunk_manager.query_embeddings(query)
qdrant_manager = QdrantManager()
query_context = qdrant_manager.search_query(query_embeddings)
#create prompt
query_prompts = chunk_manager.create_prompt(query_context,query)
AI_answer = qdrant_manager.get_ai_response(query_prompts)
return AI_answer
class FeedData(BaseModel):
data: str
class SearchData(BaseModel):
data: str
@app.post("/ask")
def search_startup(SearchData:SearchData):
query = SearchData.data
ai_answer = find_docs(query)
return {"response": ai_answer}
@app.post("/feed/add")
def feed_add(feed_data: FeedData):
try:
data = feed_data.data
ids = add_docs(data=data)
return {"response": "Document successfully added.", "doc_uuids": ids}
except ValidationError as e:
raise HTTPException(status_code=400, detail="Invalid input data.")
if __name__ == "__main__":
import uvicorn
#uvicorn.run(app, host="0.0.0.0", port=8000)
uvicorn.run(app, host=Config.HOST, port=Config.PORT, reload=Config.DEBUG)
Understanding Chunking and Embedding in RAG
Chunking and embedding are critical steps in building a Retrieval-Augmented Generation (RAG) system. These processes allow large documents to be broken down into manageable pieces and transformed into vector representations for efficient similarity search.
What is Chunking?
Chunking involves breaking down a large piece of text into smaller, more manageable sections (or “chunks”). This ensures that:
- The data remains contextually relevant.
- It avoids exceeding token limits when generating embeddings or querying a model.
- It improves retrieval precision by associating queries with specific parts of the document.
How Chunking Works
Splitting the Text
- Text is divided into smaller chunks based on a predefined strategy, such as sentence boundaries, paragraph lengths, or token counts.
- For instance, a chunk might be limited to 500 tokens to ensure compatibility with models like OpenAI embeddings.
Preserving Context
- Overlap between chunks is sometimes added to retain context between sections.
Here’s how you can implement the chunking and embeddings (data_chunk_manager.py):
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores.utils import filter_complex_metadata
from sentence_transformers import SentenceTransformer
from config import Config
import openai
class DataChunkManager:
def __init__(self):
self.text_splitter = RecursiveCharacterTextSplitter(chunk_size=900, chunk_overlap=150)
def generate_chunk(self, document):
chunks = self.text_splitter.split_documents(document)
chunks = filter_complex_metadata(chunks)
return chunks
def create_document(self, text):
document = self.text_splitter.create_documents(text)
return document
def generate_embeddings(self,texts):
openai.api_key = Config.api_key
model_name = Config.embedding_model
texts_content = [doc.page_content for doc in texts]
response = openai.Embedding.create(
model=model_name,
input=texts_content
)
embeddings = [item['embedding'] for item in response['data']]
return embeddings
def query_embeddings(self, query):
model_name=Config.embedding_model
openai.api_key = Config.api_key
query_response = openai.Embedding.create(
model=model_name,
input=query
)
query_embedding = query_response['data'][0]['embedding']
return query_embedding
Step 3: Upload Data to Qdrant & Query the Database:
Upload Data to Qdrant
Use the upload_documents function to:
- Create a unique ID for each chunk.
- Store the vector embeddings and the associated text in Qdrant.
When a user query is received
Generate its vector embedding.
- Perform a similarity search in Qdrant using search_query.
- Retrieve the most relevant text chunks for context.
(vector_db_manager.py):
from langchain_qdrant import QdrantVectorStore
from qdrant_client import QdrantClient
from qdrant_client.http.models import Distance, VectorParams, PointStruct
import uuid
import openai
from config import Config
import json
collection_name = Config.collection_name
client = QdrantClient(url=Config.qdrant_host)
class QdrantManager:
def __init__(self, collection_name=Config.collection_name, vector_size=Config.vector_size_ai_model, url=Config.qdrant_host):
self.client = QdrantClient(url=url)
self.collection_name = collection_name
self.vector_size = vector_size
self._ensure_collection_exists()
def _ensure_collection_exists(self):
try:
self.client.get_collection(self.collection_name)
print(f"Collection '{self.collection_name}' already exists.")
except:
self.client.create_collection(
collection_name=self.collection_name,
vectors_config=VectorParams(size=self.vector_size, distance=Distance.COSINE)
)
print(f"Collection '{self.collection_name}' created successfully.")
def upload_documents(self, embeddings, texts):
texts_content = [doc.page_content for doc in texts]
payloads = [{'text': text} for text in texts_content]
uploaded_ids = []
for embedding, payload in zip(embeddings, payloads):
unique_id = str(uuid.uuid4())
self.client.upsert(
collection_name=self.collection_name,
points=[
PointStruct(
id=unique_id,
vector=embedding,
payload=payload
)
]
)
uploaded_ids.append(unique_id)
print("Documents and embeddings uploaded successfully.")
return json.dumps(uploaded_ids)
def search_query(self, query_embedding, limit=3):
search_results = self.client.search(
collection_name=self.collection_name,
query_vector=query_embedding,
limit=limit
)
# Retrieve and concatenate the contexts from the search results
retrieved_context = "\n\n".join([result.payload['text'] for result in search_results])
return retrieved_context
def get_ai_response(self,prompt: str, max_tokens: int = 150, temperature: float = 0.2) -> str:
if Config.api_key:
openai.api_key = Config.api_key
else:
raise ValueError("API key must be provided")
model = Config.ai_model
response = openai.ChatCompletion.create(
model=model,
messages=[
{"role": "user", "content": prompt}
],
max_tokens=max_tokens,
temperature=temperature,
top_p=1,
n=1
)
# Extract the answer from the response
answer = response['choices'][0]['message']['content'].strip()
return answer
Step 4: Test Your RAG Workflow
- Add Data: Use the /feed/add API to upload documents.
- Ask Questions: Use the /ask API to query the system and receive AI-generated answers.
Step 5: Integrating RAG API with Drupal
Integrating your Retrieval-Augmented Generation (RAG) system with Drupal allows you to leverage its content management capabilities while enhancing it with intelligent retrieval and response generation. By connecting your Flask API to a Drupal instance, you can enable dynamic querying and content enhancement directly from your RAG system.
Edit or create the rag_integration.module file in your custom module folder
<?php use Drupal\Core\Entity\EntityInterface; /** * Implements hook_entity_presave(). */ function rag_integration_entity_presave(EntityInterface $entity) { // Check if the entity is of type 'node' and the content type is 'article'. if ($entity->getEntityTypeId() === 'node' && $entity->bundle() === 'article') {
// Extract the body field value.
$body = $entity->get('body')->value;
// Ensure the body is not empty before calling the API.
if (!empty($body)) {
// Call the /feed/add API.
$flask_api_url = 'http://:/feed/add';
$client = \Drupal::httpClient();
try {
$response = $client->post($flask_api_url, [
'json' => ['data' => $body],
]);
$result = json_decode($response->getBody(), TRUE);
// Optionally, log the response or handle errors.
if (isset($result['response'])) {
\Drupal::logger('rag_integration')->info('Content added to RAG: @response', ['@response' => $result['response']]);
} else {
\Drupal::logger('rag_integration')->error('Failed to add content to RAG.');
}
} catch (\Exception $e) {
\Drupal::logger('rag_integration')->error('Error calling /feed/add API: @message', ['@message' => $e->getMessage()]);
}
}
}
}
Similarly, we can create a page in Drupal and use /ask API to fetch the response from Qdrant DB,
RAG Architecture
RAG (Retrieval-Augmented Generation) integrates information retrieval with language generation, enabling AI to fetch relevant data from external sources and generate accurate, context-rich responses. It combines a retriever model for knowledge fetching and a generator model for response creation.
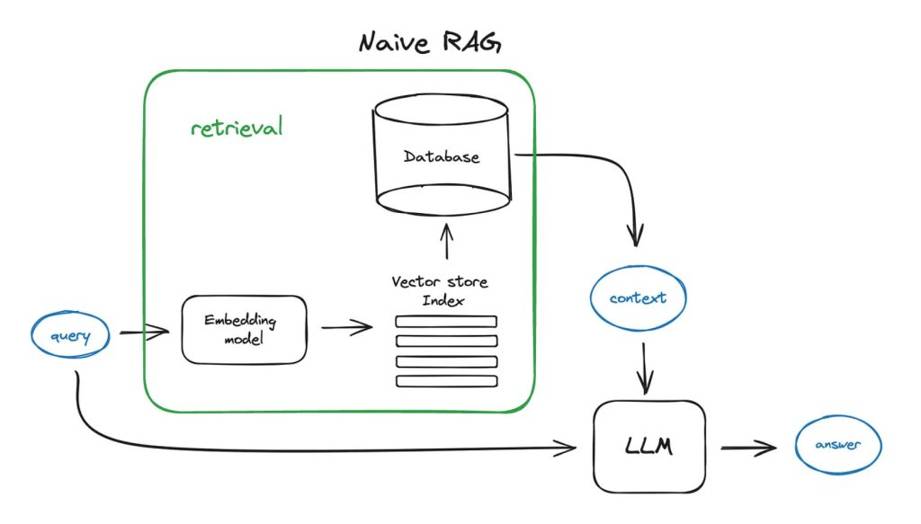
RAG Architecture
Conclusion
Integrating a Retrieval-Augmented Generation (RAG) system with Flask APIs and Drupal allows seamless content ingestion, semantic search, and dynamic content augmentation. By leveraging tools like Qdrant, LangChain, and Drupal, we created an efficient system for enhanced data retrieval and personalized user experiences, enabling scalable AI-driven content delivery.
