
Data Quality with PyDeequ: A Comprehensive Guide
Inadequate data quality can adversely affect both machine learning models and the decision-making process within a business. Unaddressed data errors can result in lasting repercussions, manifesting as blemishes and jolts. It is imperative in today’s landscape to implement automated tools for monitoring data quality, enabling the timely identification and resolution of issues. This proactive approach fosters greater confidence in the integrity of data and bolsters efficiency in data handling. Consequently, adopting automated data quality monitoring should be regarded as a strategic imperative for enhancing and sustaining an organization’s data systems.
In this step-by-step guide, we’ll take a look at the different types of data quality checks available in AWS pyDeequ, so you can get a better understanding of how it works.
What is PyDeequ?
PyDeequ is a Python library that provides a set of tools for data quality assessment and validation in large datasets. It allows users to define data quality checks, measure data quality metrics, and identify issues or anomalies within their data. PyDeequ is often used in data preprocessing and quality assurance tasks in data analytics and machine learning workflows.
Setting up PyDeequ on PySpark

Once you have installed these dependencies, you’ll be ready to use PyDeequ for data quality checks and assessments on your datasets within a PySpark environment.
Implementing PyDeequ
Main components

Profiling: Profiling is the process of gathering basic statistics and information about the data. In PyDeequ, the profiler provides summary statistics, data type information, and basic data distribution insights for each column in your dataset. It helps you understand the characteristics of your data quickly.
Analyzer: The analyzer component goes beyond profiling and allows you to compute more advanced statistics and metrics for your data. This includes metrics like uniqueness, completeness, and other custom-defined metrics. Analyzers help you gain a deeper understanding of data quality issues in your dataset.
Constraint Suggestion: Constraint suggestion is a powerful feature of PyDeequ that automatically generates data quality constraints based on the profiling and analysis results. It suggests constraints such as uniqueness, completeness, and data type constraints that you can apply to your data to improve its quality.
Verification: Verification is the process of running data quality checks on your dataset using the defined constraints. PyDeequ’s verification component enables you to create and run data quality checks to validate whether your data conforms to the defined constraints. It provides detailed reports on the results of these checks, helping you identify data quality issues.
Data Quality Metrics: PyDeequ includes a set of predefined data quality metrics that you can use to measure and monitor the quality of your data. These metrics include measures like data completeness, distinctness, and uniformity, among others.
Anomaly Detection: PyDeequ also offers anomaly detection capabilities to identify unusual or unexpected patterns in your data. This can be particularly useful for spotting outliers or data points that deviate significantly from the norm.
Check Builder: PyDeequ provides a convenient CheckBuilder API that allows you to construct data quality checks programmatically. You can define custom checks based on your specific data quality requirements and apply them to your data.
These main components of PyDeequ work together to help you assess, analyze, and improve the quality of your data within a PySpark environment. By leveraging these components, you can gain valuable insights into your data and ensure it meets the necessary quality standards for your analytics and machine learning projects.
Available Data Quality Checks
● Completeness Checks: These checks make sure that the specified fields in your data structure are filled with non-empty values. AWS pyDeequ offers functions to check the completeness of columns and find the missing values.
● Uniqueness Checks: Uniqueness checks make sure there are no duplicates in a particular column or set of columns. You can also determine the uniqueness rate of columns using AWS PyData.
● Consistency Checks: The purpose of consistency checks is to ensure consistency across data values. With the help of AWS pyDeequ, you can identify the values that are not consistent in categorical columns. This way, you can detect data entry errors or discrepancies.
● Functional Dependency Checks: These checks determine whether one type of column defines another type of column.
● Pattern Checks: In a pattern check, data is validated against pre-defined patterns (such as email addresses or phone numbers). With AWS PyDeeq, you can check whether your data matches those patterns.
● Value Distribution Checks: Value distribution checks give you an idea of how the values are distributed within a single column. With the help of AWS pyDeequ, you can see how the unique values are distributed, which helps you to see where the data is skewed and where the data is balanced.
● Custom Checks: With AWS PyDeeq, you can create your controls based on your business rules. With this flexibility, you can address domain-specific data quality issues.
Definitions of supported checks
pyDeequ provides ~40 constraints that we can verify on our dataset based on the above scenario for checking the quality of your data.
| Constraint | Definition |
| hasSize | Asserts on Data Frame Size. |
| isComplete | Asserts on a column completion. |
| hasCompleteness | Asserts non-null values/total_values. |
| areComplete | checks all listed columns have non-null values. |
| areAnyComplete | Asserts any completion in the combined set of columns. |
| isUnique | Asserts on a column’s uniqueness. |
| hasUniqueness | Asserts any uniqueness in a single or combined set of key columns. |
| hasDistinctness | Asserts distinctness in a single or combined set of key columns. |
| hasUniqueValueRatio | Asserts a unique value ratio in a single or combined set of key columns. |
| hasNumberofDistinctValues | Asserts the number of distinct values in the column. |
| hasHistogramValues | Asserts on column’s value distribution. |
| hasEntropy | Asserts on a column entropy. |
| hasMutualInformation | Asserts on a piece of mutual information between two columns. |
| hasApproxQuantile | Asserts on an approximated quantile. |
| hasMinLength | Asserts on the minimum length of the column. |
| hasMaxLength | Asserts on the maximum length of the column. |
| hasMin | Asserts on the minimum value in the column. |
| hasMax | Asserts on the maximum value in the column. |
| hasMean | Asserts on the mean of column values. |
| hasSum | Asserts on the sum of column values. |
| hasStandardDeviation | Asserts on the standard deviation of the column. |
| hasApproxCountDistinct | Asserts on the approximate count distinct of the given column. |
| hasCorrelation | Asserts on the Pearson correlation between two columns. |
| hasCompleteness | Asserts on completed rows in a combined set of columns. |
| haveAnyCompleteness | Asserts on any completion in the combined set of columns. |
| satisfies | Asserts on the given condition on the data frame( Where Clause). |
| hasPattern | Matches the regex Pattern. |
| containsCreditCardNumber | Verifies against a Credit Card pattern. |
| containsEmail | Verifies against an Email pattern. |
| containsURL | Verifies against a URL pattern. |
| containsSocialSecurityNumber | Verifies against the Social Security number pattern for the US. |
| hasDataType | Verifies against the fraction of rows that conform to the given data type |
| isNonNegative | Asserts that a column contains no negative values. |
| isPositive | Find ratio positive_values/total_values. |
| isLessThan | Asserts that in each row, the value of columnA < the value of columnB. |
| isLessThanOrEqualto | Asserts that in each row, the value of columnA ≤ the value of columnB. |
| isGreaterThan | Asserts that in each row, the value of columnA > the value of columnB. |
| isGreaterThanOrEqualTo | Asserts that in each row, the value of columnA ≥ to the value of columnB. |
| isContainedIn | Asserts that every non-null value in a column is contained in a set of predefined values. |
Example:
Pydeequ supports simple sequential addition of constraints on any Pyspark data frame and returns the quality check report in both JSON/CSV formats.
Below is a sample code for adding constraints:

Generated Report:
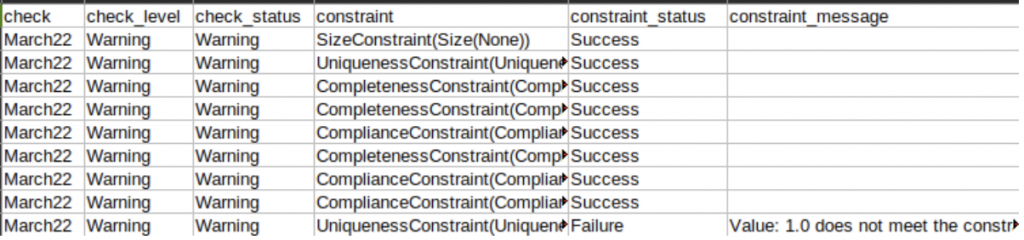
Conclusion
Data quality is one of the most important aspects of your data-driven business. AWS PyDeequ provides a complete suite of data quality controls that you can easily integrate into your workflow. With the help of its functions, you can improve the accuracy, uniformity, and dependability of your data sets, resulting in more informed decisions and insights.
In this step-by-step guide, we’ve covered everything you need to know about AWS PyDeequ’s various data quality controls, including completeness, uniqueness, custom, and more. With this knowledge in hand, you’re better equipped to make sure your data is as good as it can be, helping your organization reach its full potential.
