
Configuring AWS Lambda as a Kafka Producer with SASL_SSL and Kerberos/GSSAPI for Secure Communication
Kafka is a distributed streaming platform designed for real-time data pipelines, stream processing, and data integration. AWS lambda, on the other hand, is a serverless compute service that executes your code in response to events, managing the underlying compute resources for you. In organizations where Kafka plays a central role in streaming and data integration, implementing a serverless, event-driven solution that processes files and seamlessly produces records to Kafka is an efficient and scalable approach.
In this blog, we’ll walk through how to configure an AWS Lambda function as a Kafka producer, reading files from Amazon S3 and sending data to Kafka in event-driven batch mode. We’ll use the confluent-kafka-python library with SASL_SSL and GSSAPI configurations for secure communication. Since pre-built Linux wheels of confluent-kafka-python do not support SASL Kerberos/GSSAPI, we must install librdkafka and its dependencies separately and build confluent-kafka. We will containerize the Lambda function along with confluent-kafka build, deploy via AWS ECR (Elastic Container Registry), and integrate with AWS Secrets Manager for passing Kafka credentials and certificates.
Read More: Efficient Data Migration from MongoDB to S3 using PySpark
Architecture
The architecture below demonstrates a data pipeline that utilizes various AWS components to show how a containerized Lambda can be used to produce records for Kafka.
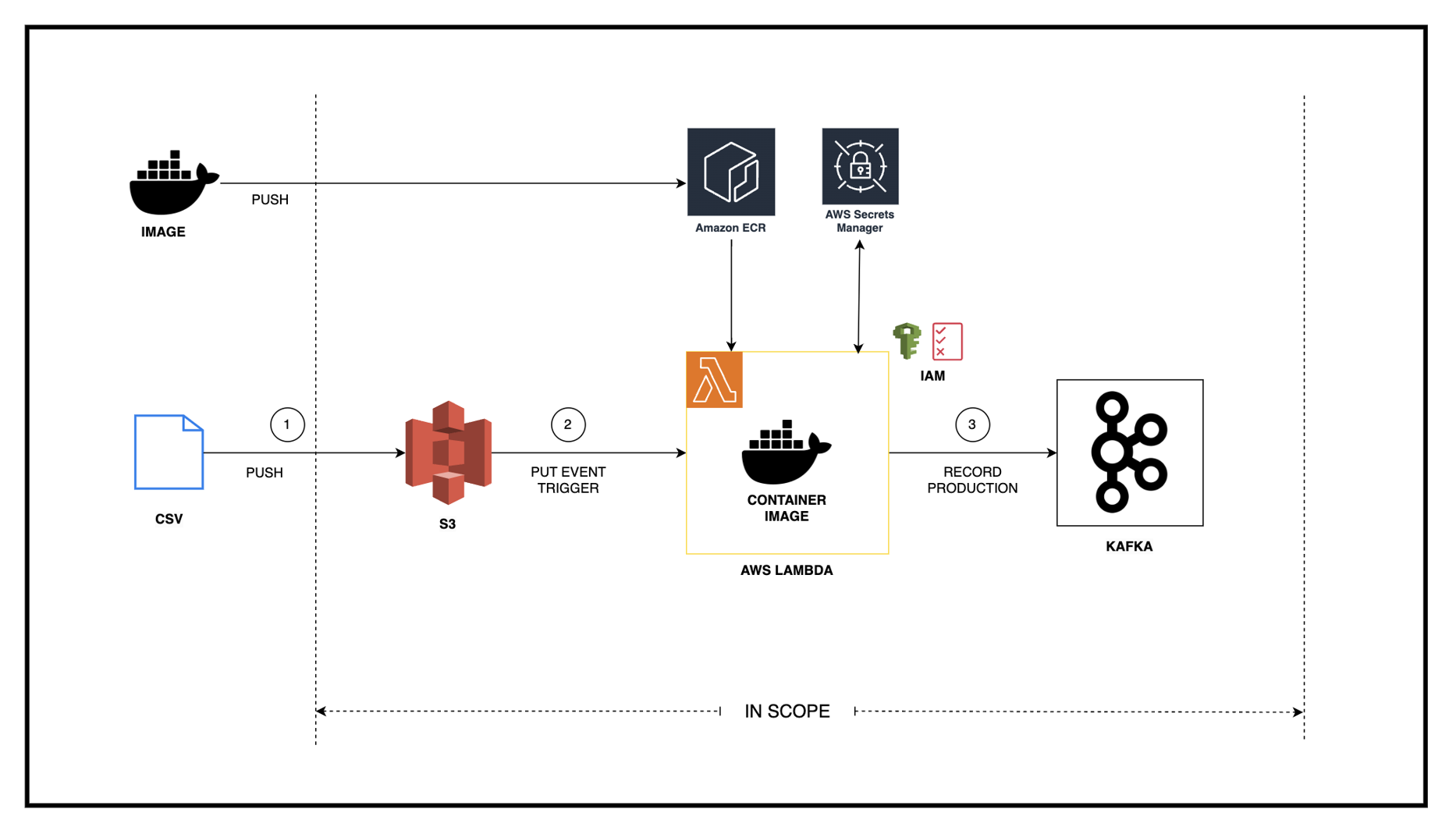
Steps to Configure AWS Lambda as Kafka Producer
1. Create a Python-based Lambda code for the producer.
First, we need to create a Python-based Lambda code for our producer and later will package it as a Docker container. We will use the confluent-kafka-python library for this.
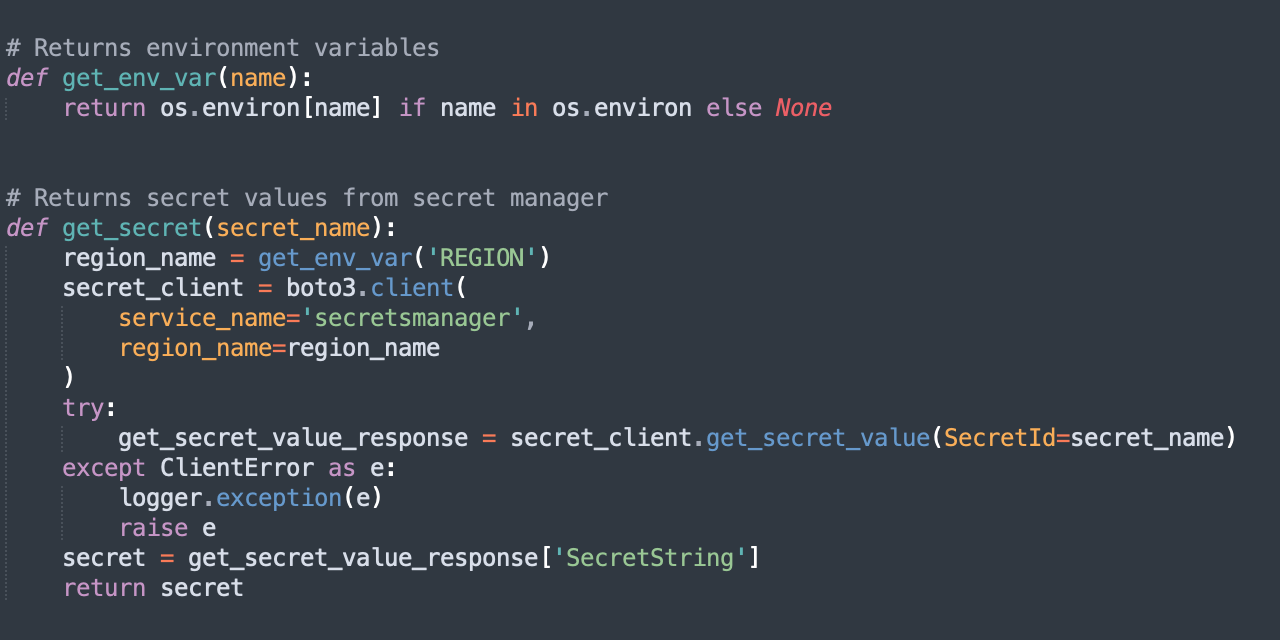
- Define functions to retrieve environment variables and secret values from the secret manager.
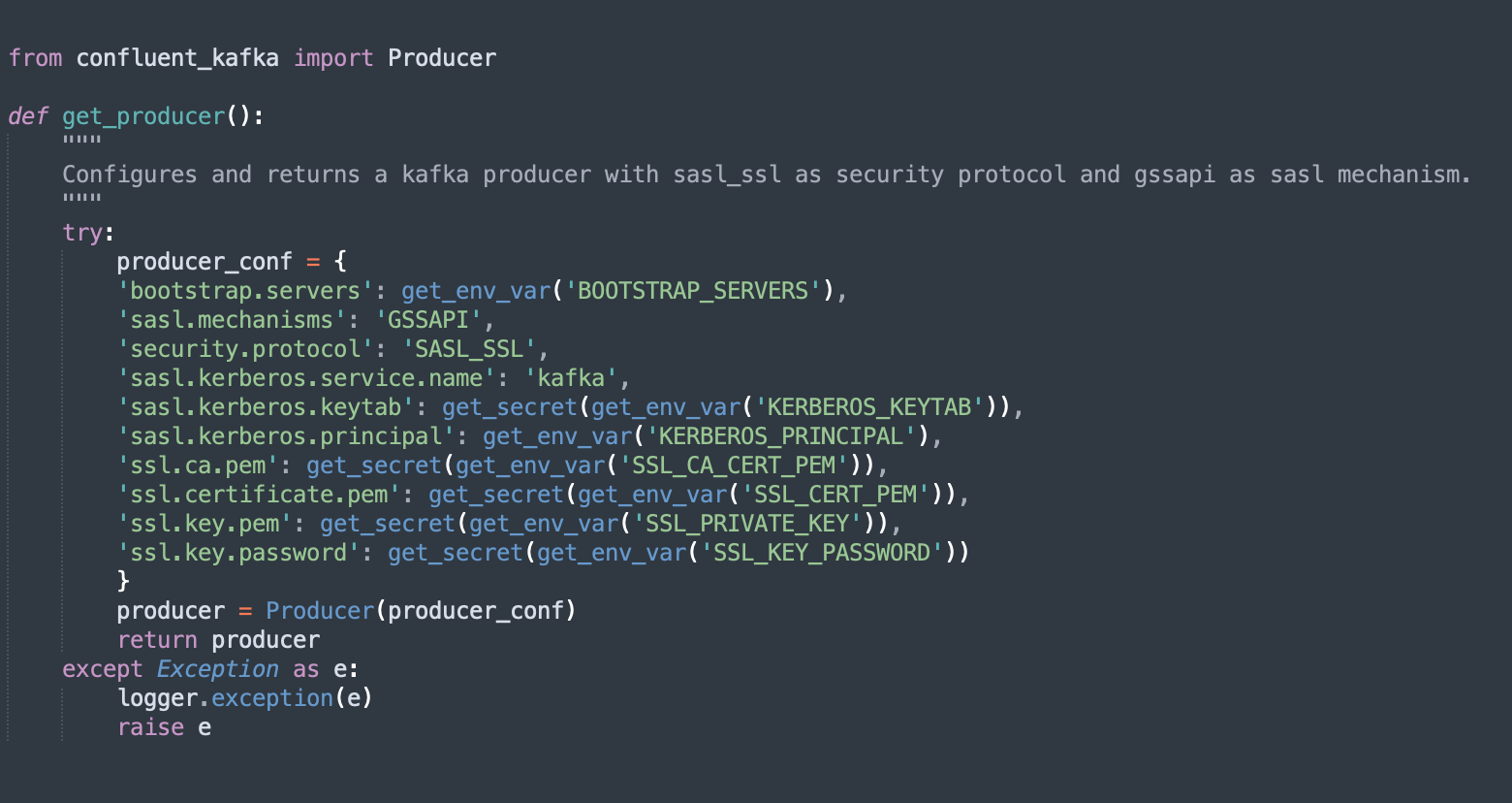
- Define producer configuration
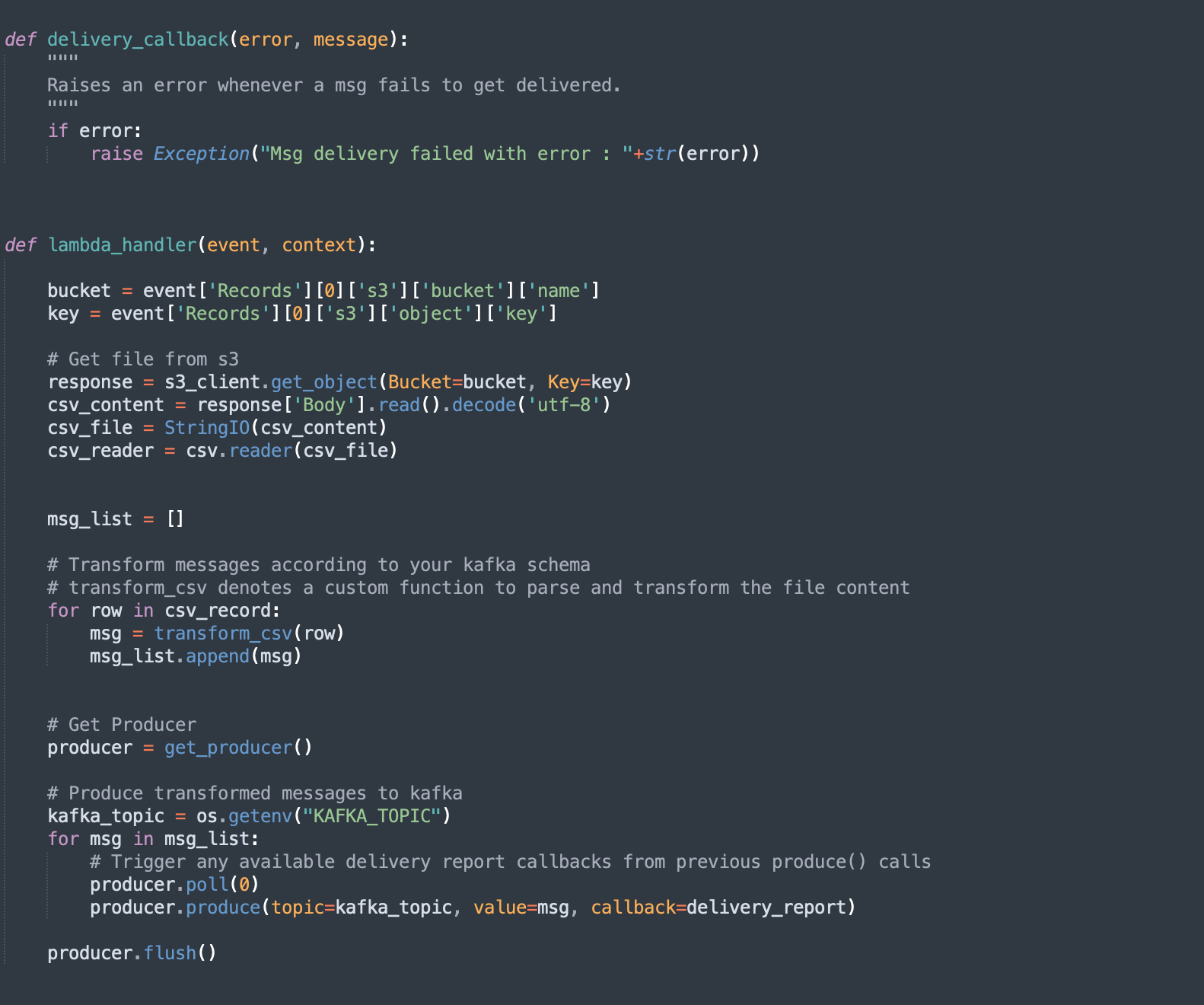
- Define lambda handler
Read More: Driving Efficiency and Cost Reduction: Kafka Migration to AWS MSK for a Leading Advertising Firm
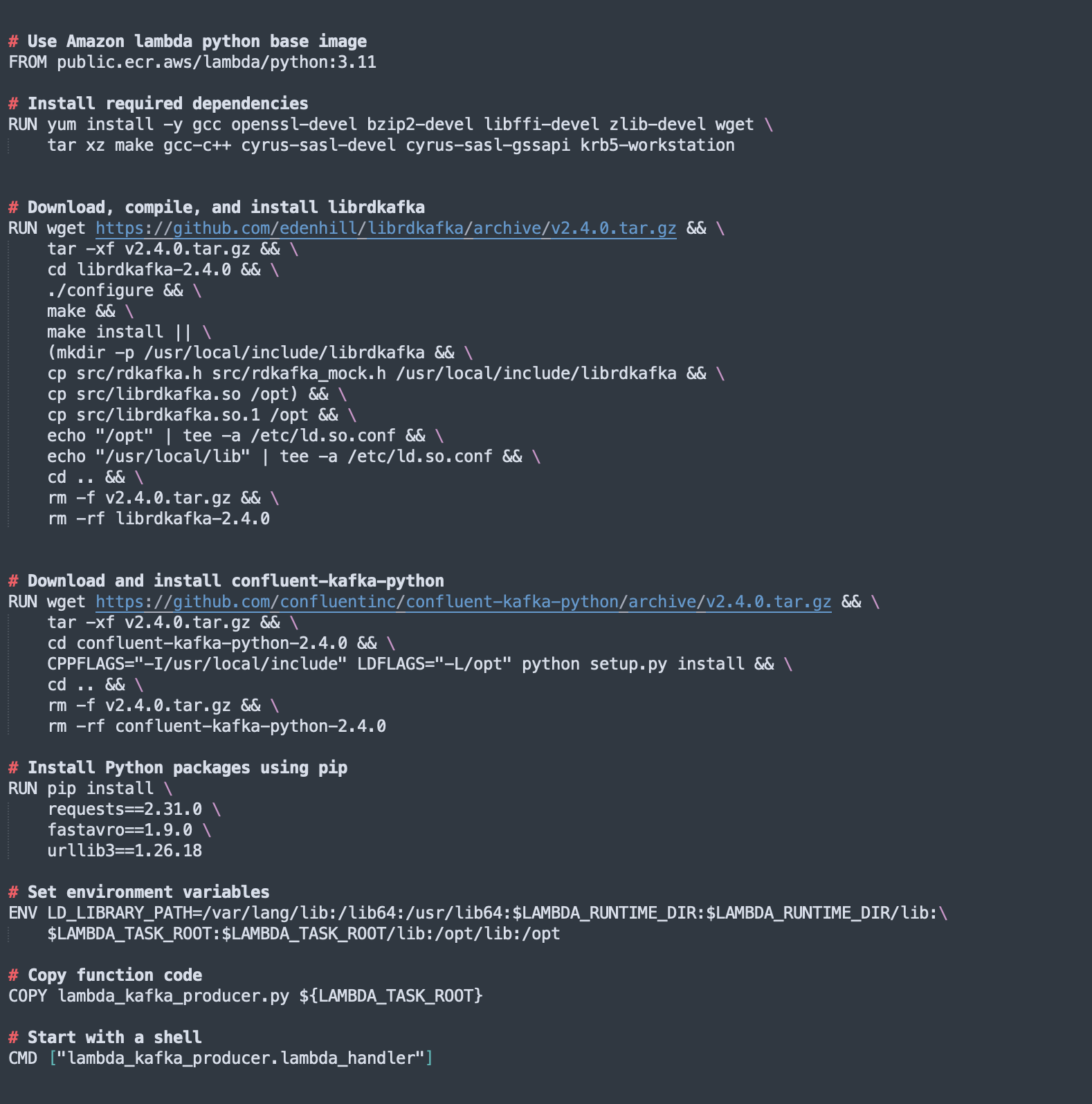
2. Create a Dockerfile
Here’s a simple Dockerfile to containerize the Lambda function with the necessary dependencies including librdkafka and confluent-kafka-python, enabling SASL_SSL communication using Kerberos/GSSAPI.
3. Build and Push Docker Image to ECR
Once the Dockerfile is ready, we can build and push the image to AWS ECR.

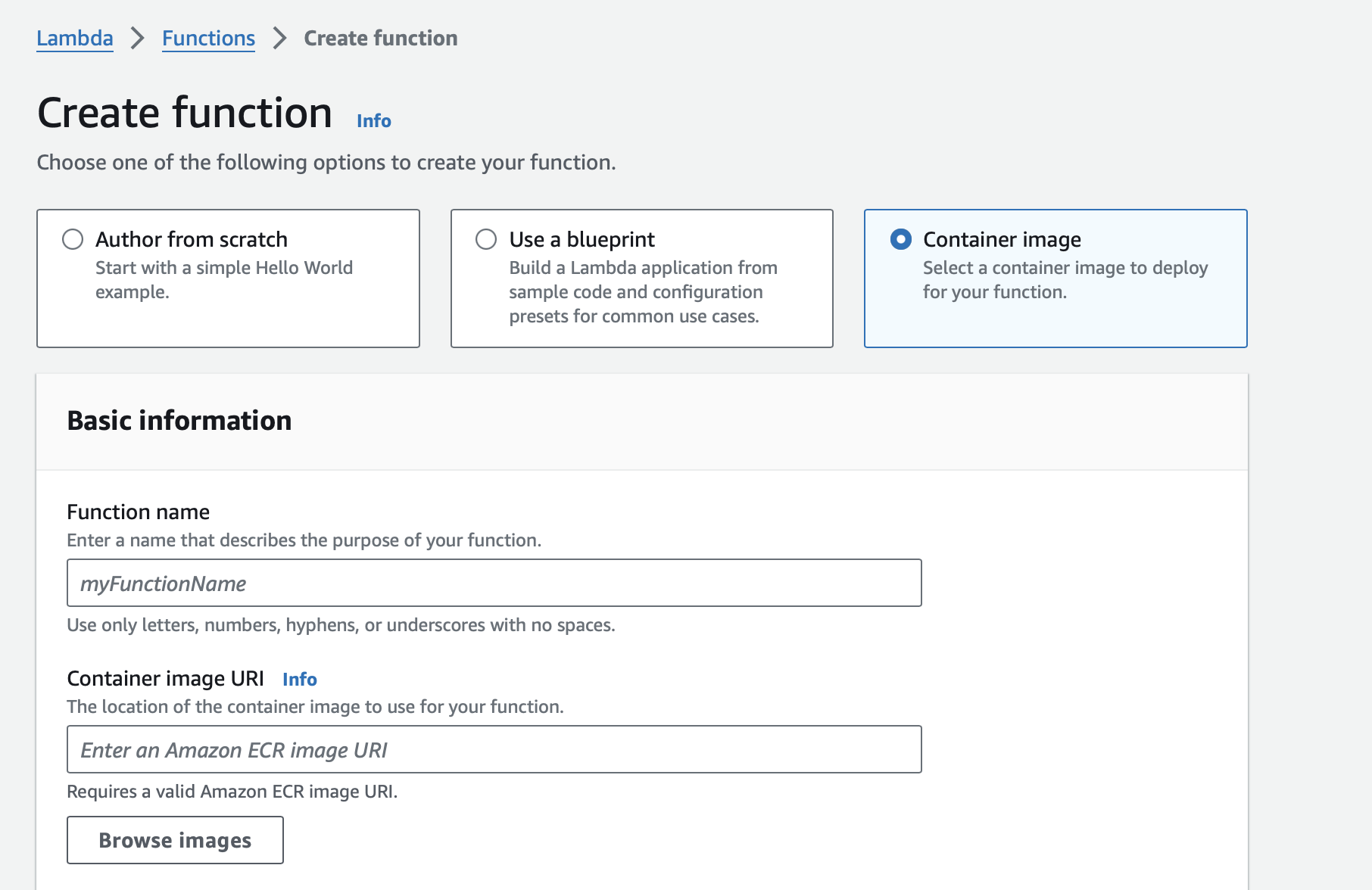
4. Create Lambda Function from ECR Image
In the AWS Management Console, create a new Lambda function and choose the Container image option. Select the image from your ECR repository.
5. Configure Kafka Secrets in AWS Secrets Manager
Store Kafka credentials, including the SSL certificate and Kerberos Keytab, in AWS Secrets Manager. This ensures the credentials are securely retrieved at runtime.
6. Set Environment Variables
Configure the environment variables for the Lambda function to access secrets and other variables.
7. Provide IAM permissions
Provide necessary IAM permissions for:
- Accessing S3 from AWS Lambda.
- Accessing ECR from AWS Lambda.
- Accessing Secret Manager.
8. Testing the Lambda Function
In order to test the lambda function before deploying and running on AWS:
- Run the docker image for lambda producer and provide all necessary env variables.

- Send a sample event using the curl command in another window. The csv file name used in the event should be present in s3 location.
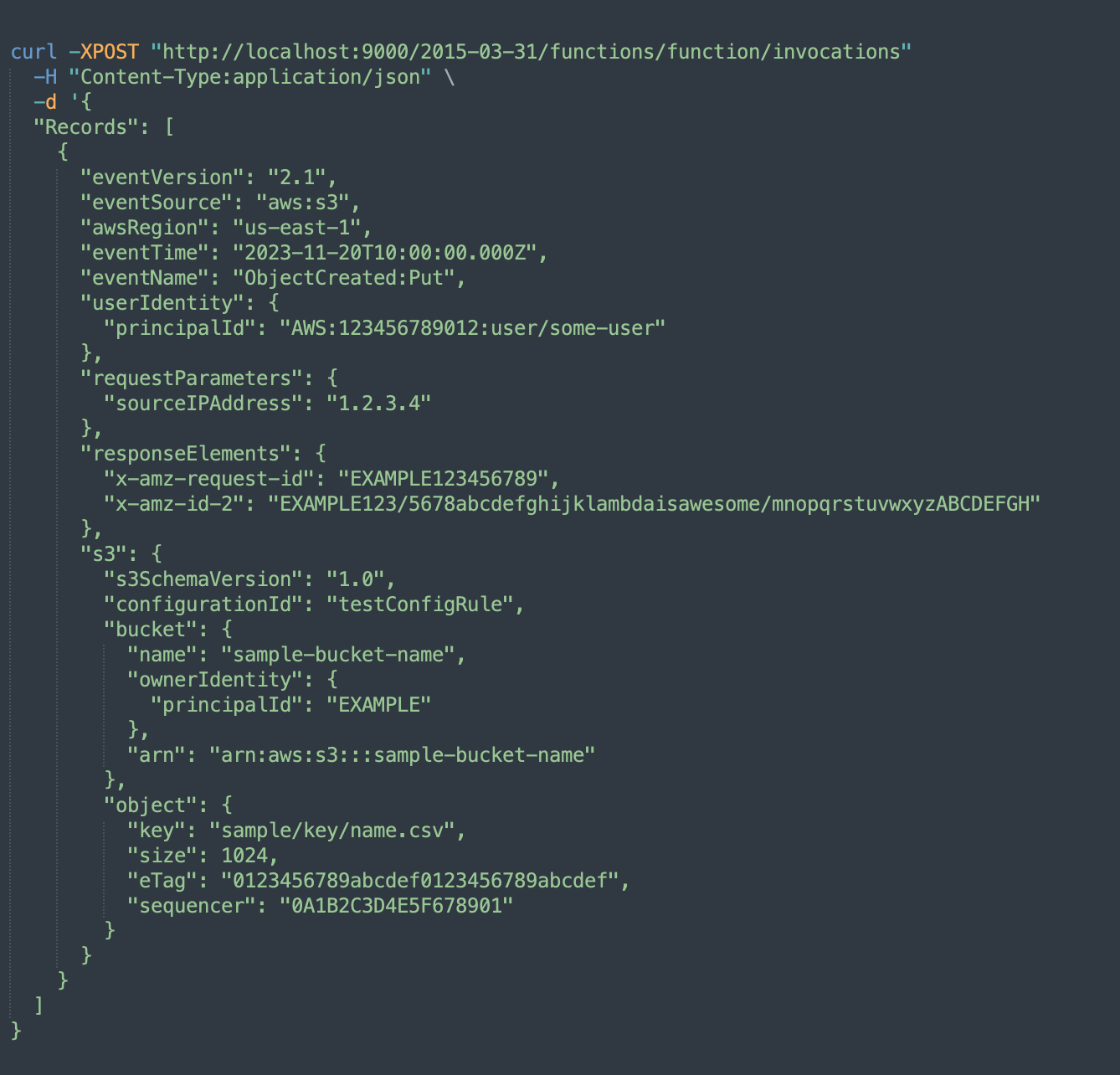
- Lambda container hosted on a local machine should be triggered, and processing should start.
- Lambda should be able to read all CSV records transform them according to the lambda logic and produce them to Kafka topic.
- Data should be available in the Kafka topic.
- Once all scenarios are tested you can deploy your image to AWS and start using Lambda as a Kafka producer.
Conclusion
Containerizing AWS Lambda allows us to efficiently manage complex dependencies and extend its capabilities with external libraries like confluent-kafka-python and librdkafka. This provides a secure way to integrate AWS Lambda with Kafka as a producer using SASL_SSL and GSSAPI. Additionally, it ensures a consistent stable environment across Dev, Test, and Prod Stages. This architecture offers a scalable, secure solution for building robust data pipelines that seamlessly integrate with S3 and Kafka.
