
Building Efficient Data ETL Pipelines: Anatomy of an ETL [PART-1]
In today’s data-driven world, businesses rely on timely, accurate information to make critical decisions. Data pipelines play a vital role in this process, seamlessly fetching, processing, and transferring data to centralized locations like data warehouses. These pipelines ensure the right data is available when needed, allowing organizations to analyze trends, forecast outcomes, and optimize their operations. As the volume and complexity of data continue to grow, building efficient and reliable data pipelines has become essential for maintaining a competitive edge.
ETL Pipelines
ETL (Extract, Transform, and Load) is a structured framework used for extracting data from various data sources, transforming it into a usable and standardized format, and loading it into destination systems like data warehouses or databases for analytical and reporting purposes.

Overview of ETL Pipeline
-
- Extraction – It is the initial step in any of the ETL pipelines. In this step, data is gathered from various sources like databases, APIs, streaming platforms, etc. The data that is extracted is in the raw format to maintain its structure and integrity.
- Transformation – After the data has been extracted using the extraction process it needs to be transformed in accordance with the business requirements to ensure quality and compatibility with the destination systems. Transformation may include, but is not limited to cleaning, filtering, and aggregation.
- Loading – After the transformation step data is then transferred to destination systems such as data warehouse etc. Where it can be used for further analytical and reporting purposes.
Importance of ETL Pipelines
The rate of expansion of data generation has led to an increase in numerous data sources for data consumption. As a result, data now needs to be accessed from these data sources simultaneously. However, none of the data provided by these data sources can be used directly. This is where the use of ETL comes in.
An ETL pipeline takes care of the migration of data, its refinement, and transformation along with the accumulation of multiple data sources. With the help of ETL data quality can be applied to the data ensuring standardization.
Some of the key important aspects of using ETL pipelines are:
-
- Comprehensive Business Overview – As data is scattered across multiple systems and applications, gaining a holistic view of the data for the business can be challenging. ETL helps in combining these data sources and provides a more comprehensive view of the business.
- Automation – Since data is being generated continuously there is a need to automate the processes. ETL not only optimizes repetitive data processing but also ETL tools can be used to automate these processes for faster and more efficient functioning.
- Data Governance – This is related to the usefulness, availability, consistency, and integrity of the data. The addition of an abstraction layer in the ETL pipeline can ensure data governance by preserving data security and lineage.
- Scalability – Since the volume and complexity of the data is increasing at a rapid pace there is a need to scale your resources along with time to be able to handle the size of the data to ensure accurate and insightful business reports. There are multiple ETL tools that provide the serverless capability to build your pipelines without being worried about scaling resources.
Critical Components of ETL
An ETL pipeline can be considered as a package of several components that are vital and facilitate the extraction, transformation, and loading of the data.
-
- Data Sources – Repositories where data resides before it has been extracted for processing. These data repositories can be Relational Databases, NoSQL Databases, files, streaming sources, etc. It is crucial to identify the source and establish a connection with it to ensure retrieval of desired data.
-

Various Data Sources
- Extraction Mechanism – It is necessary to define the data extraction method. It can be batch processing, real-time processing, or change data capture (CDC). It is necessary to make a choice based on the business requirements since it will be responsible for data pipeline complexity, data latency, and infrastructure cost.
- Data Processing and Transformation Engine – After the successful extraction of data it is required to create a well-defined transformation engine which will ensure any gaps in data such as missing values, outliers, etc. are being taken care of. Also, data is aggregated and enriched as per business needs. Tools such as Apache Spark, AWS Glue, Talend, etc. can be used. A well-defined engine results in consistency, quality, and efficient use of underlying resources.
- Data Loading/Storage – Once the data has undergone extraction and transformation layer it needs to be stored somewhere. The choice of storage may vary depending on the business use case such as Data Warehouse, NoSQL Databases, Data Lake, etc. The type of storage system chosen will affect the speed, flexibility, and cost of analyzing the data. For example, to store vast amounts of raw data in a cost-effective way data lake might be considered, while for more fast and complex queries on data, one might choose data warehouses as an option for storage.
-
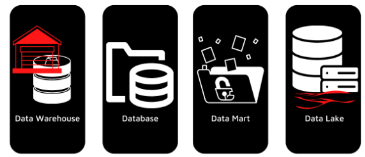
Data Storage Options
- Data Governance and management – A set of practices and processes are implemented to ensure the quality of data, the accuracy of data, and most importantly privacy and security of the data. Various tools can be used to achieve the following. Adhering to this component of the ETL pipeline helps maintain user trust and prevents any unnecessary data leaks.
- Pipeline Management and Orchestration – The above-discussed components need to be combined, to achieve this these components are broken down into multiple tasks, and rules are applied to ensure tasks are executed in a linear fashion and the correct sequence. Orchestration provides capabilities for error handling, monitoring, scheduling, and logging functionalities. Once the orchestration component has been implemented successfully it ensures a smooth flow of the data pipeline with minimal manual intervention.
Types of ETL
ETL can be of different types based on the user and the system requirements.
-
- Batch ETL:
- The data is processed as a single batch at scheduled time intervals.
- The entire batch set is transformed and loaded into the target system.
- Batch ETL:
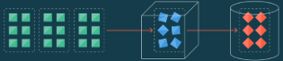
Batch ETL Data Flow
-
- Real-time ETL:
- Data is processed as it is available in the source system.
- This ETL generates near real-time data for the system that needs real-time analysis, fraud detection, or other decision-making.
- Real-time ETL:
-
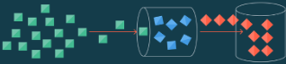
Real-Time ETL Data Flow
- Initial/full-load ETL:
- This ETL is a one-time job.
- This usually runs initially at the time of setup of the data repository or if we need to re-load the repository because of any issue or data blow-up.
It is used to process the complete historical data at once to start up the warehouse.
- Incremental ETL:
- This is a scheduled load that processes only the data which has been changed since the last run.
- A time or other markers are maintained to fetch the latest data in each scheduled run.
- This system requires special handling of data deletion as only modification/new records are handled.
- Initial/full-load ETL:
NOTE – The above topics capture the fundamental essence of the ETL pipeline, including its key components and their role in effective data management. Part 2 of this blog delves deeper into the complexities encountered during the setup and execution of the pipeline. It explores best practices specifically associated with Fact and Dimension tables to provide more granular insights and enhance our understanding of effective data-handling strategies.
