
Spark SQL Query Optimization Techniques for Data Engineers
SQL (structured query language) is the building block of data engineering, it plays a significant role in managing, manipulating, organizing, and retrieving data in relational databases. In data engineering, huge volumes of data with increasing complexity are processed on a daily basis, and to manage it, data engineers work on distributed systems like Spark. On writing the SQL queries with Spark, query performance is to be considered carefully. In this blog, we will focus on essential SQL query optimization techniques to maintain efficient data pipelines.

Spark Optimization
Key Optimization Techniques for Data Engineers
1) Partitioning—an alternative to indexing in Spark
Partitioning divides the data into smaller and manageable subsets based on a specific column which minimizes the amount of data Spark needs to scan when running queries.; it works similarly to an index that helps to quickly locate and retrieve data.
What role does partitioning play?
When data engineers work with distributed systems like Hadoop, Spark, etc., partitioning the data can significantly improve how the query performs. Spark SQL prunes irrelevant partitions and reads only the data that matches the filtering criteria.
Use Case:
1) We can use partitioning where range-based queries are used. Example: Sales data over time.
2) When using queries that frequently filter or join on a specific column, for example – date, region, etc. We can partition the dataset on that column to avoid unnecessary shuffling.
Performance Analysis: Partitioned vs. Non-Partitioned Query Plans
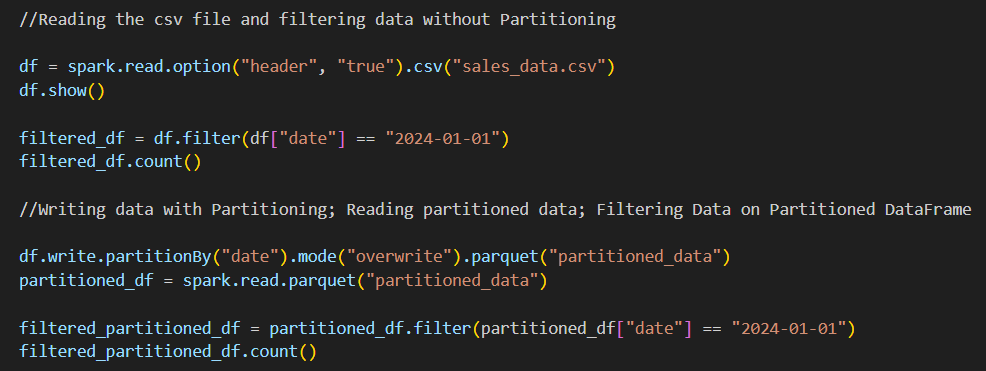
Partitioning on a date column
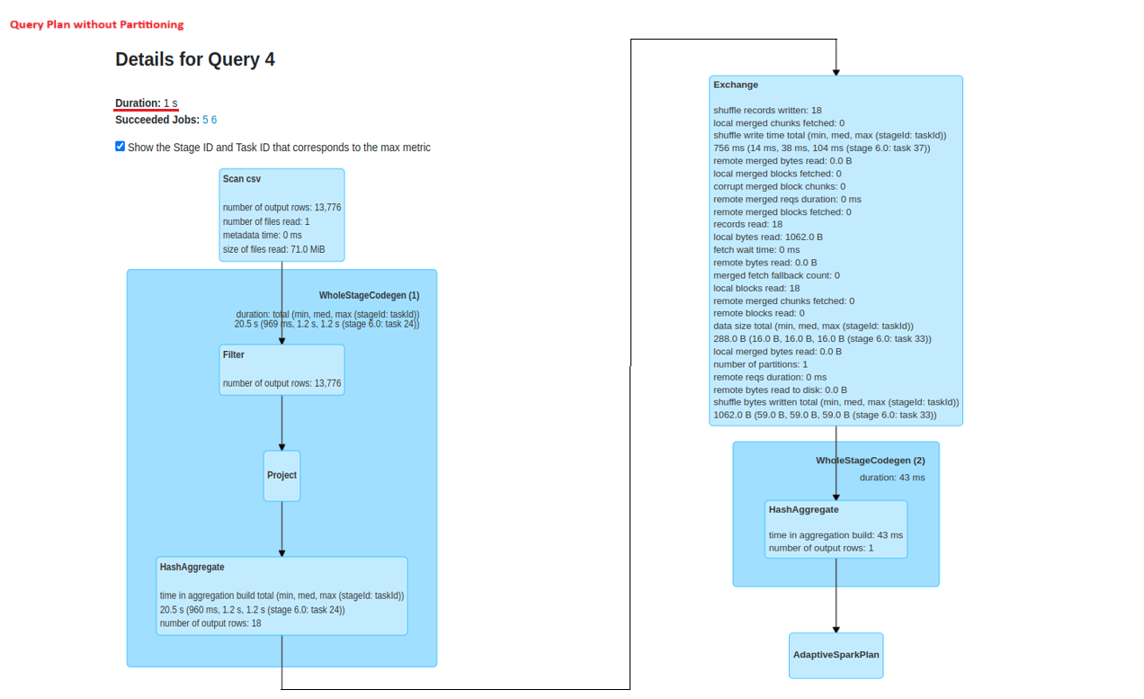
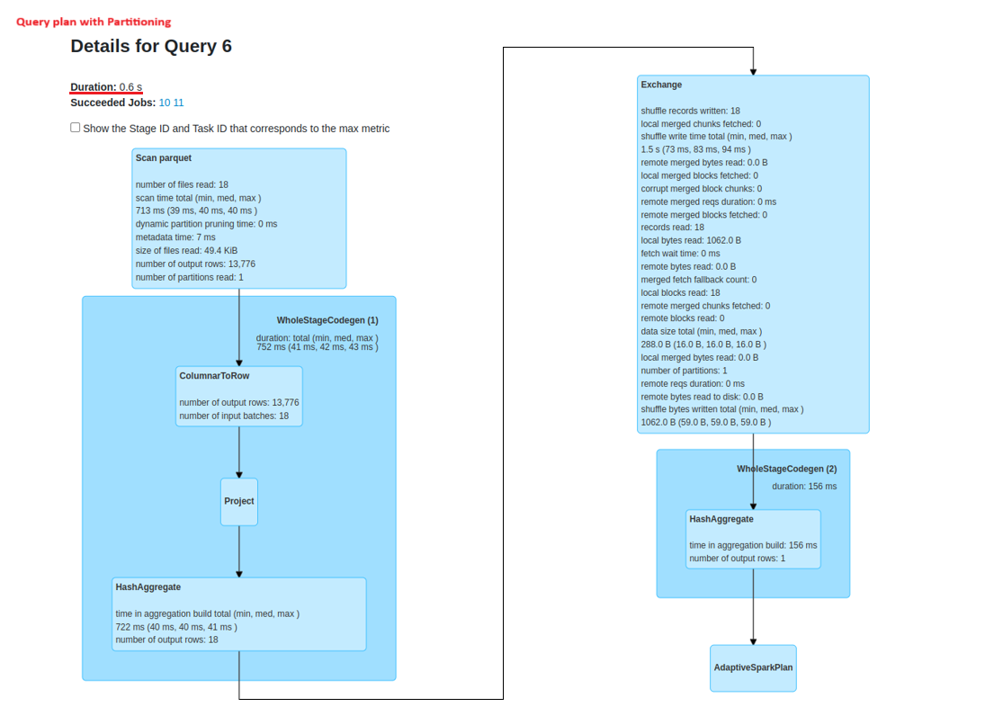
Partitioning Strategies in Spark
a) Range Partitioning
Range Partitioning in Spark partitions the datasets based on some specific value ranges—time-series data. When partitioning on date and timestamp columns, Spark only reads those partitions when the query executes improving performance.
Example in Spark:

Range Partitioning
b) Hash Partitioning
Hash partitioning in Spark evenly distributes data across partitions which improves query parallelism and prevents data from getting skewed. Use this strategy when the distribution of data is unpredictable to ensure a balanced workload spread across the executors.
Example in Spark:

Hash Partitioning
2) Query Optimization in Spark SQL
The query execution plan defines the steps the database engine follows in order to retrieve and process data. By reviewing and making fine adjustments, we can enhance query performance as it makes the identification of the skewed distribution of data, wide transformations, and plenty of not-required data shuffles easy.
Spark-specific techniques for query optimization
1) We can use repartition() or coalesce() in Spark SQL to optimize data distribution across nodes and ensure that operations like join, group, and aggregation are processed efficiently.
Examples :
a) repartition() for optimizing join operations
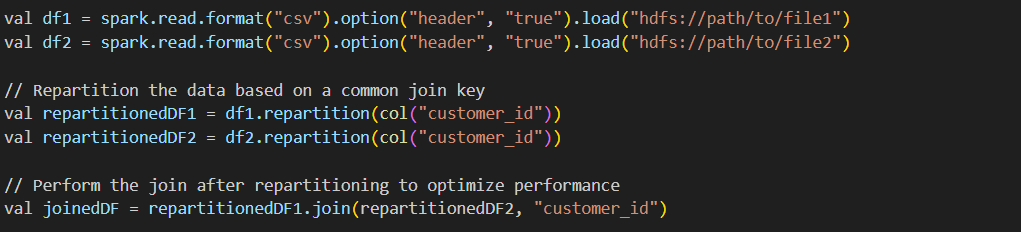
repartition() example
b) coalesce() for reducing partitions after aggregation
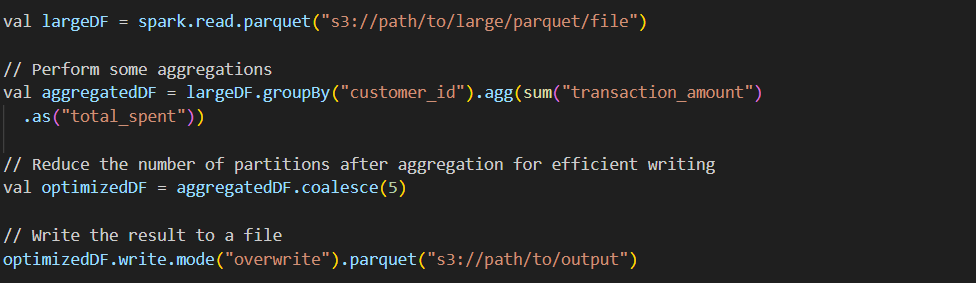
coalesce() example
c)repartition() with skewed data
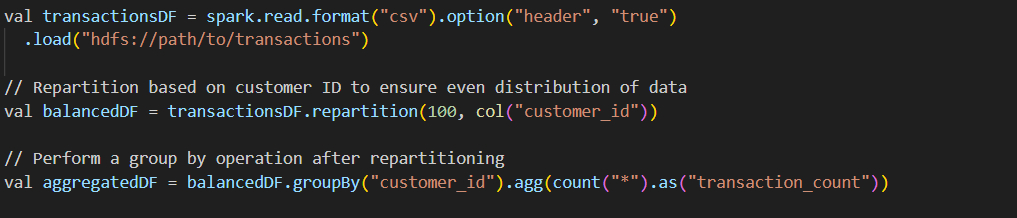
repartition() with skew
2)
a) Use of broadcast joins in Spark SQL
In Spark, a broadcast join helps by sending the smaller dataset to all the worker nodes present in the cluster when joining a large dataset with it, therefore reducing the need for data shuffling and improving the execution time.
What role does broadcast joins play?
In distributed systems like Spark, when we use broadcast join, no data is moved between worker nodes, eliminating expensive shuffling operations.
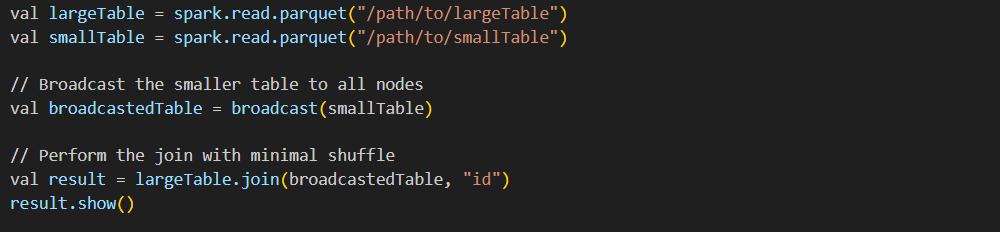
Broadcast join example
Use Case:
When joining a lookup table for example – customer demographics data with a larger dataset of customer transactions, the join happens much faster when we broadcast the smaller table.
b) Partition Pruning
In Spark when we have partitioned data stored in Parquet, ORC, etc. formats, using this catalyst optimization technique helps to automatically skip scanning irrelevant partitions.

Partition pruning example
Use Case:
If the dataset is partitioned by date, queries should include partition filters like WHERE year=2024 so that only the relevant partitions are scanned.
c) Caching and Persistence in Spark
Using Spark’s cache() and persist() methods, we can store the intermediate query results that are used multiple times within the job. This helps to cut down on the re-computational part, thereby improving the execution speed.
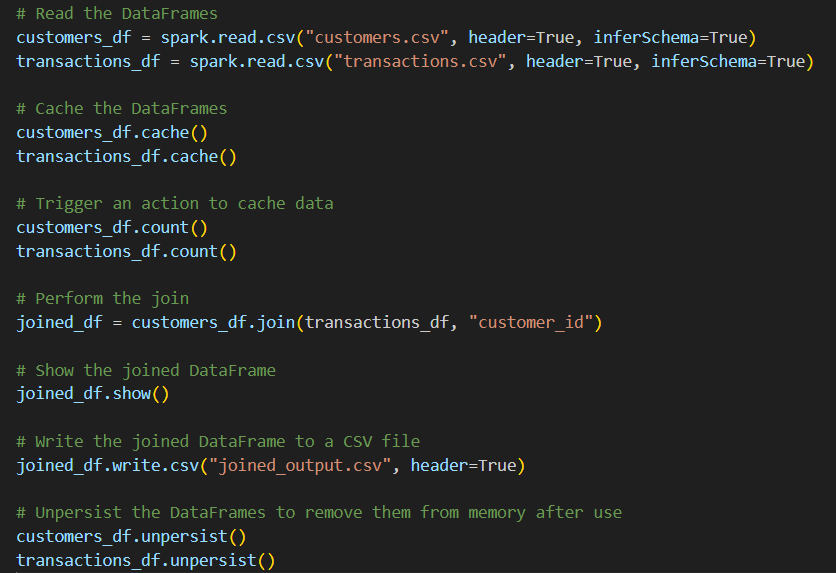
Caching in Spark
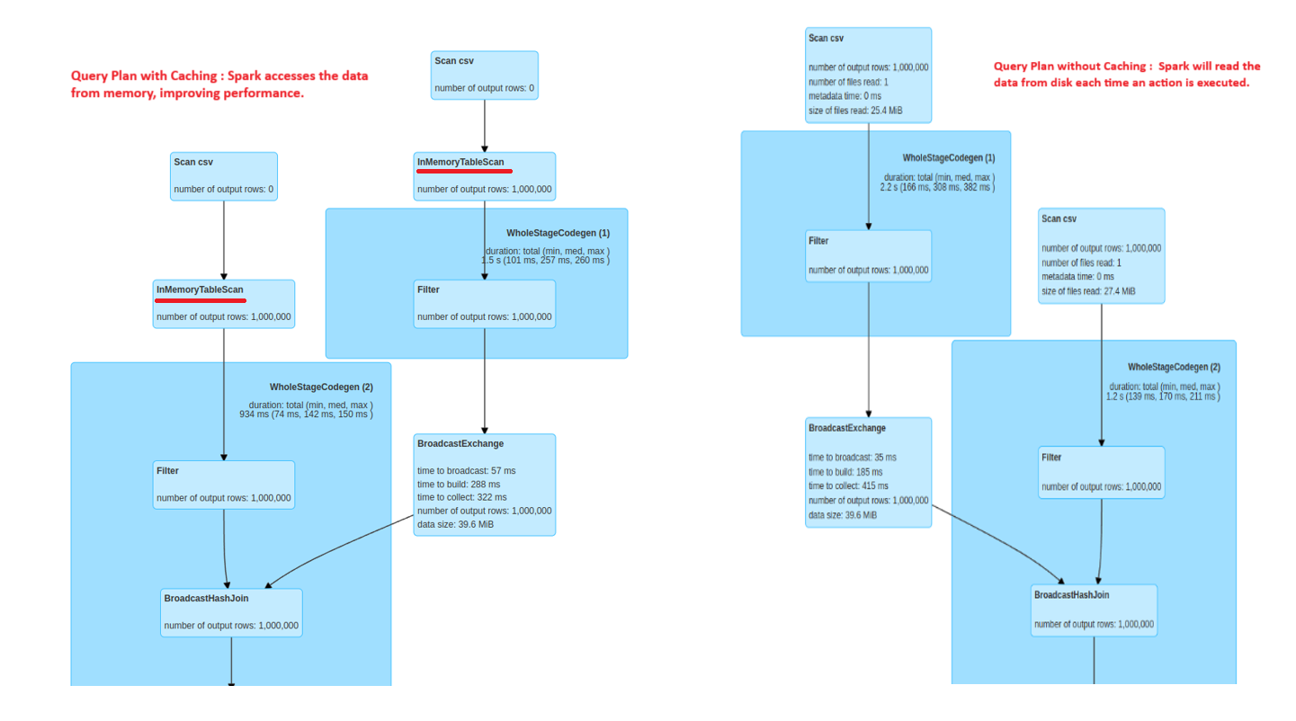
Use Case:
i) When there is iterative data processing, caching critical intermediate dataframes can help to avoid re-computation.
ii) Used when joining the datasets or while performing complex transformations.
3) Views and Materialized Views
Views: provide an abstraction layer over complex data; help in maintaining readability and manageability without storing the query results.
Materialized views are used for storing the result of a frequently accessed or computationally expensive query and updating it at regular intervals. Used for analytics and auditing purposes.

Materialized Views example
Use Case:
In a data warehouse, constantly calculating customer-level information like average order value, a materialized view on the aggregated data can speed up the query.
4) Adaptive Query Execution (AQE) in Spark
A dynamic optimization technique is used in Spark that adjusts the query execution plan at runtime itself, unlike static techniques where optimizations are set prior to execution. It helps with skewed data and reduces shuffle partitions. It’s helpful where data size and distribution is not known in advance.
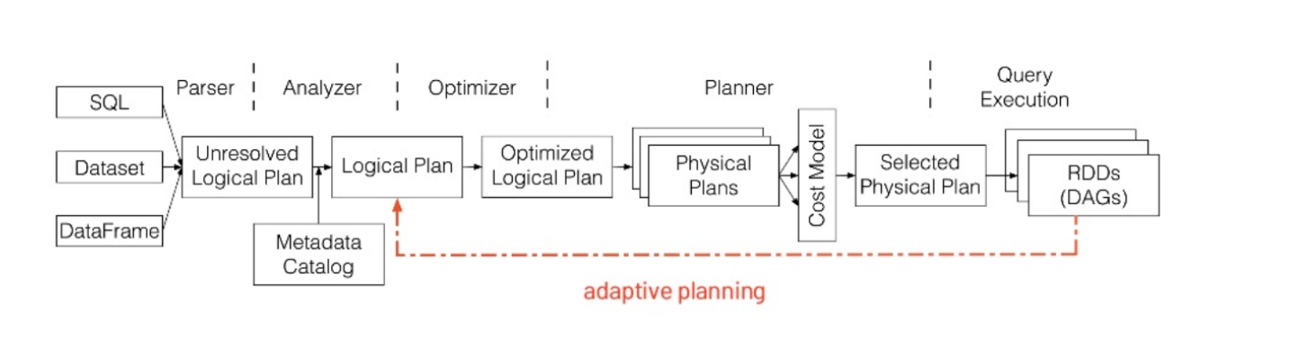
Spark AQE Framework
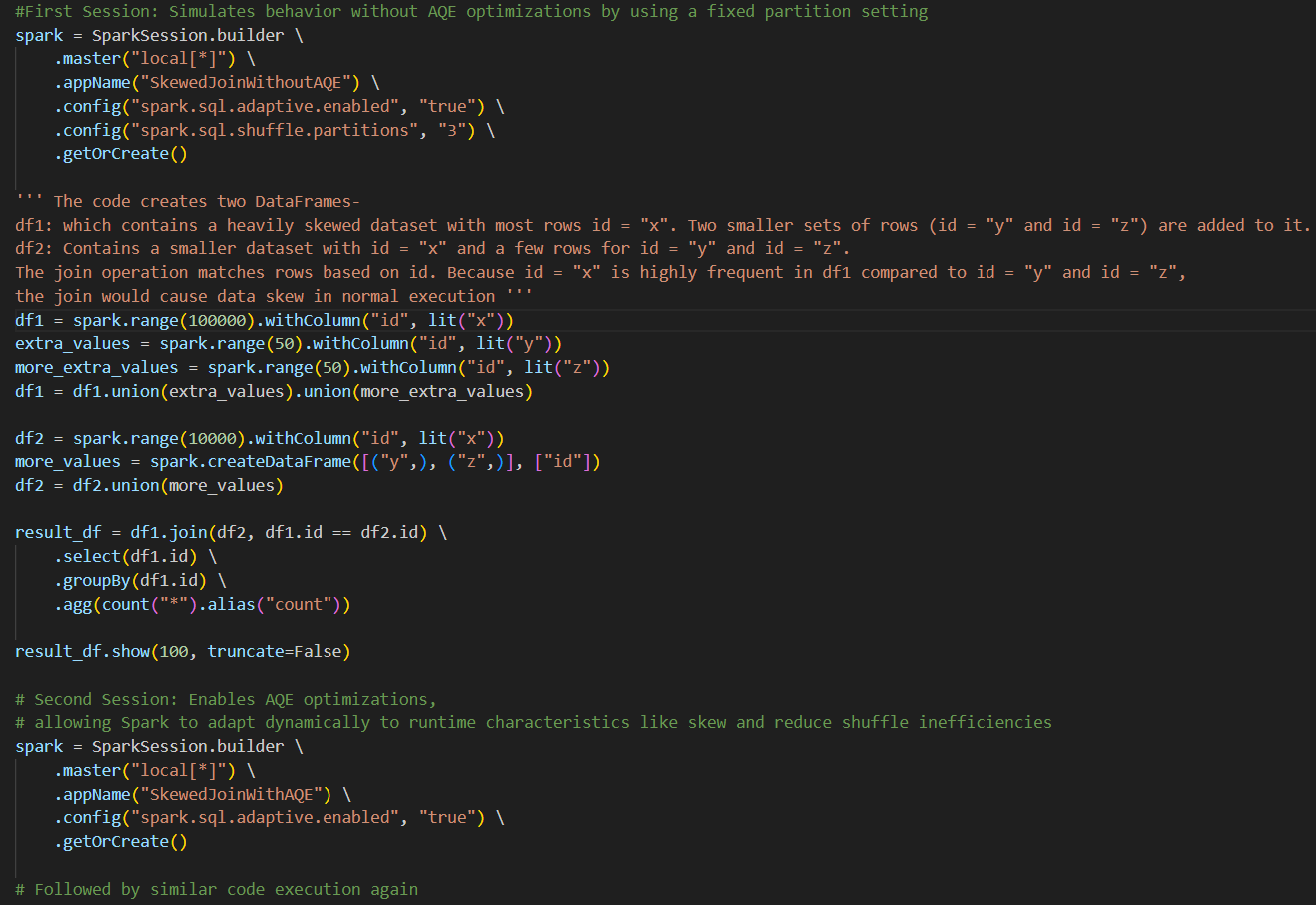
AQE Example
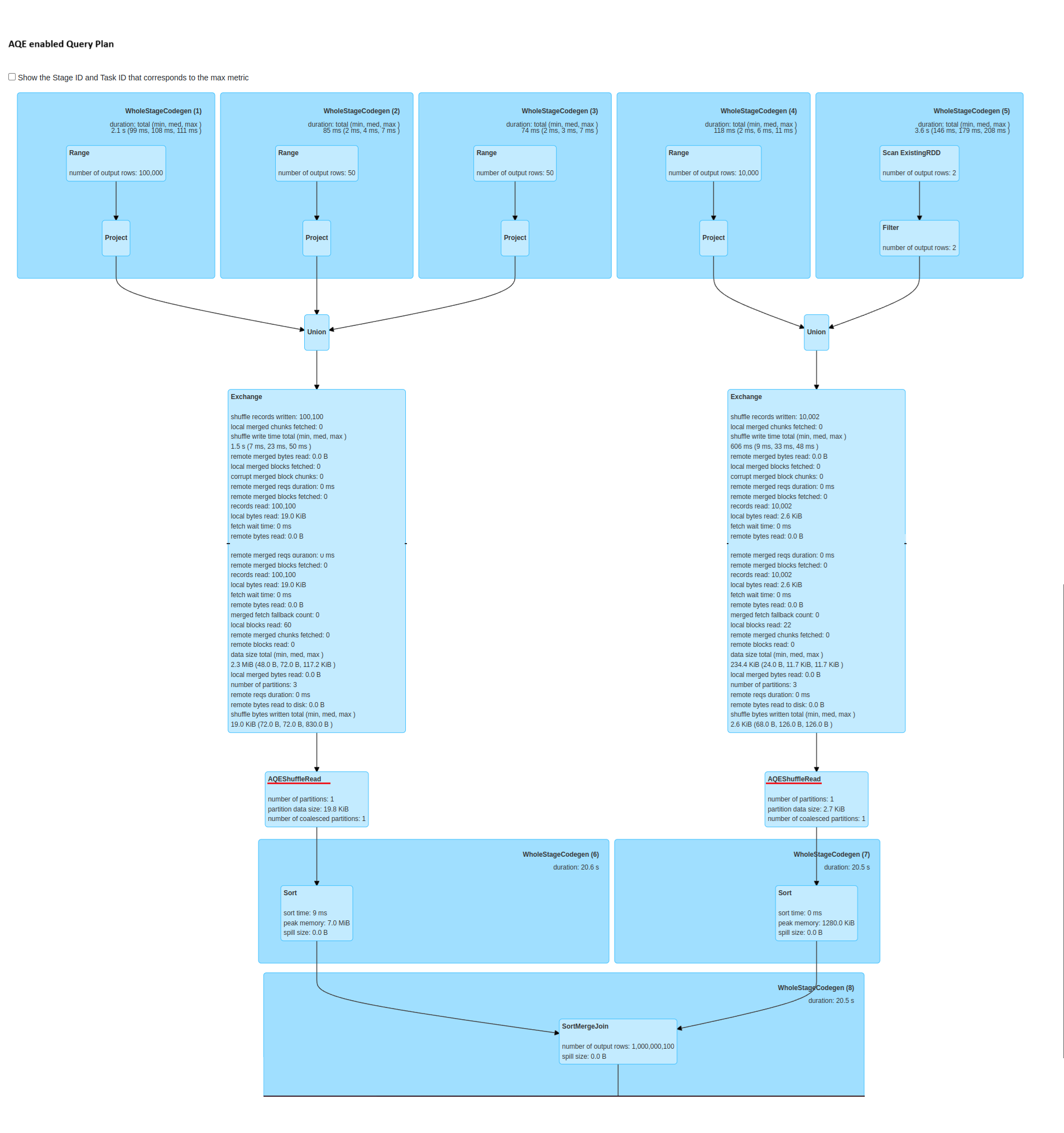
AQE in the following scenarios:
- Dynamic Partitioning: AQE helps in optimizing shuffle partitions by merging or splitting them based on the size of the shuffled data to minimize the skew.
- Skew Handling: AQE detects and adjusts for skewed data by changing join strategies dynamically at runtime.
- Broadcast Join Decisions: AQE can auto-choose to broadcast a smaller dataset when joined with a large dataset to reduce shuffling.
With AQE:
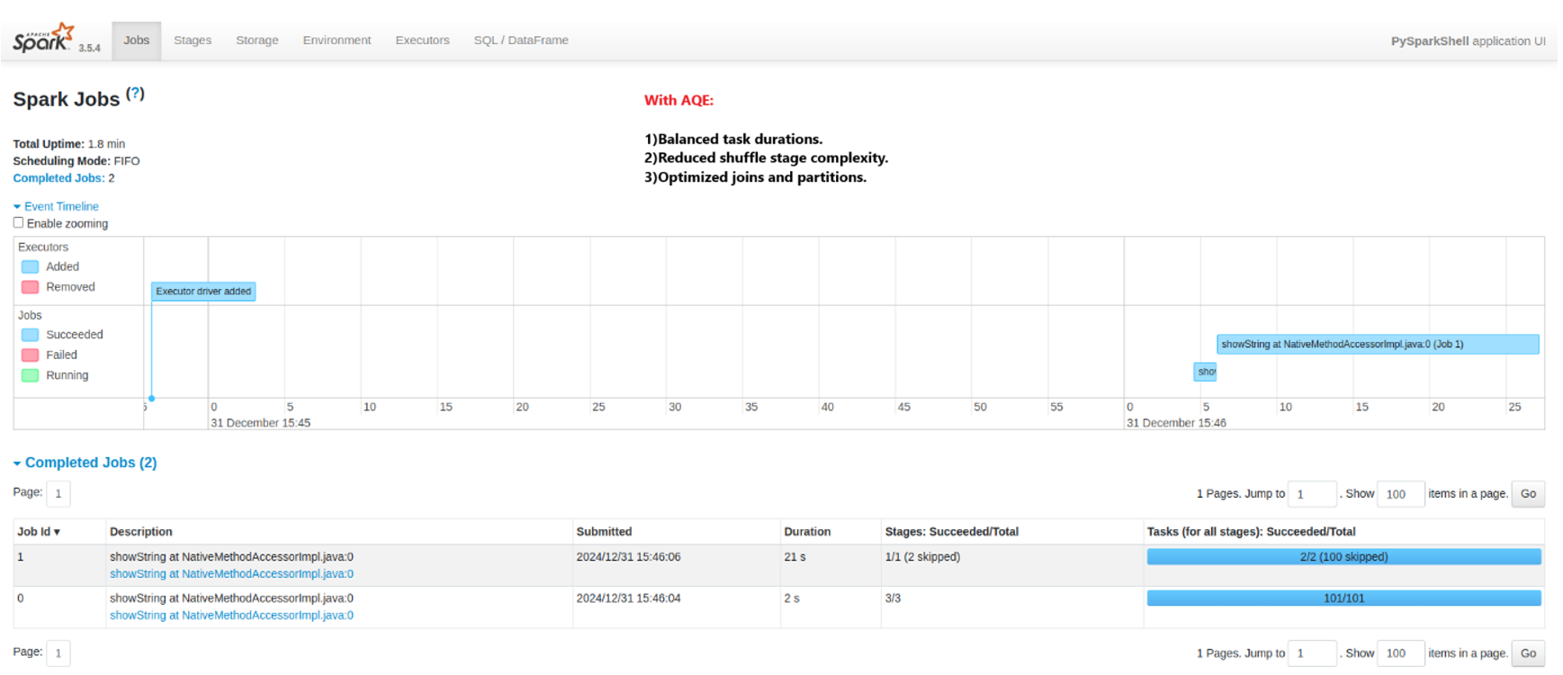
Without AQE:

5) Parallel Query Execution and Resource Allocation
In Spark, when querying large datasets, configuring the number of executor cores and required memory allocates the resources efficiently and ensures the cluster is not under-utilized.
By enabling parallel query execution for long-running queries, the multi-core processors help to speed up the queries.
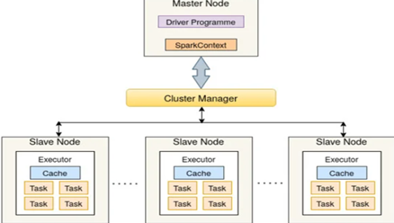
Master vs Slave node
6) Normalization and Denormalization
Normalization improves data consistency and integrity by organizing the columns and tables and reducing redundancy and anomalies while insertion, deletion, or updating. Denormalization reduces costly joins in analytical queries by combining related tables, especially for read-heavy workloads.
Use Case:
In a star schema for the analytics use case, fact tables can be denormalized by pre-joining dimensions, reducing the need for complex joins.
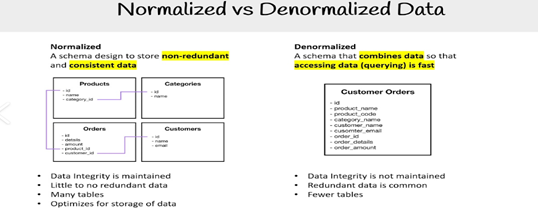
Normalization and Denormalization
7) Using Proper Data Types
Selecting the appropriate data type when writing Spark SQL queries is crucial. Using smaller data types to reduce storage can improve the query performance.
For example:
- Use INT instead of BIGINT for smaller integer values.
- Use INT for IDs rather than STRING. This will speed up comparisons.
- Use fixed-width types like CHAR(10) instead of VARCHAR.
8) Avoiding Cartesian Joins and Inefficient Query Patterns
Cartesian joins, multiply every row from a table with every other row from another table, creating an explosion of data. Some side-effects in Spark can be like:
a) Increase in processing time – more data present to shuffle and sort.
b) Higher consumption of memory-intermediate results causing memory spills.
c) Network overhead-unnecessary shuffling across nodes.
How to Avoid It:
- By specifying join conditions.
- Pre-filtering data with filters like WHERE or HAVING before the join.
- Checking query plans.
Use Case:
Suppose working with two large tables—customers and transactions. If mistakenly created a cross-join, we will get rows where customers are paired with transactions they are not related to.
Cross join example
Instead, use:
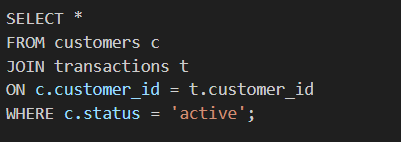
Using appropriate joins
9) Monitoring and profiling
1) Perform routine database maintenance tasks.
2) Implement monitoring and profiling tools to review query performance.
3) Utilizing tools such as SQL execution plans, or tools provided by cloud platforms like Azure to monitor query performance.
10) Query Rewriting
a) Using Joins over Subqueries
Convert correlated subqueries into more efficient join operations.
For example:

Correlated subqueries
Instead, use:
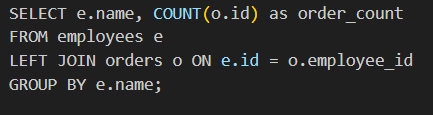
Using appropriate joins
b) Only select the required columns.
Don’t use SELECT *, list the columns needed.
c)Optimize Joins
Use inner joins when possible, as they are typically faster than outer joins.
d) Use group by columns with fewer distinct values.
As the database has to store fewer groups by keys, it leads to faster query time.
e) Avoid using an order-by clause in subqueries.
Here, the query will have to be run and then sorted, which is time-consuming.
f) Limit and offset
When fetching large result sets, it helps to control the number of rows returned.
11) Real-world scenario: optimizing ETL processes
If there’s an ETL flow that loads daily transactional data of customers into a data warehouse. Here’s a practical optimization approach for it.
a) Using Incremental Loads
Instead of reloading entire data into tables, load only new or updated data.
b) Optimize Data Transfer
If using cloud-based storage, compress the data before transfer and use efficient file formats for reduced I/O.
c) SQL Optimization
For transformations, write efficient SQL queries. Apply partitioning and Spark strategies to minimize scan time.
Continuous monitoring and adaptation are keys to maintaining a high-performing data infrastructure. By employing the Spark techniques discussed in this blog, we as data engineers can ensure that data operations are efficient and scalable.
Happy Reading and Learning, Newers!!
